Welcome to AJKLILI's Daylight Blog!
My tech notes-
Design Data-Intensive Applications
Reading notes for the book talking about what aspects to think from during data-intensive application design
-
Container Orchestration
Orchestration
When we divide our applications into small pieces – microservices – orchestration is required.
Deployment
All application components must run in a coordinated manner. An orchestrator should help us deploy application components as they are required and they should run in the right order.
Configuration
It is not easy to manage configuration in distributed environments. An orchestrator should manage this configuration and the configuration should be available anywhere a container needs it.
Resilience
If one application component fails, the orchestrator should keep the application healthy, if possible.
Scaling up/down
The microservices concept allows application components to be replicated to increase application performance if needed. If no extra power is required, we should be able to decommission these replicas to save resources.
Node distribution
To ensure high availability, we will provide a pool of orchestrated compute nodes. This way, we will distribute all application components on different nodes. If some of these nodes die, the orchestrator should ensure that the components running on those nodes run automatically on other healthy ones.
Networking
Because we distribute applications within different hosts, the orchestrator will need to provide the required application component interactions. Networking is key in this situation.
Publishing
The orchestrator should also ensure a way to interact with running application components since our application’s purpose is to provide a service to customers.
State
An application component’s state is hard to manage. Therefore, it is easier to orchestrate stateless components. This is why people think of containers as ephemeral artifacts. We learned that containers have their own life cycles and that they are not really ephemeral. They exist on hosts until someone deletes them, but orchestration should schedule these components wherever it is permitted. This means that a container’s state should be managed in a coordinated way and that components should run with the same properties everywhere. Application components have to maintain their status when they are moved to another host. In most cases, we will run a new, fresh container if a component dies, instead of trying to restart an unhealthy one.
Storage
If some application components require storage, such as for persistence data, the orchestrator should provide an interface to interact with the host’s available storage providers.
Kubernetes
Kubernetes is closer to the virtual machine application’s lift and shift approach (move application as is to a new infrastructure). This is because the Kubernetes pod object can be compared to virtual machines (with application processes running as containers inside a pod).
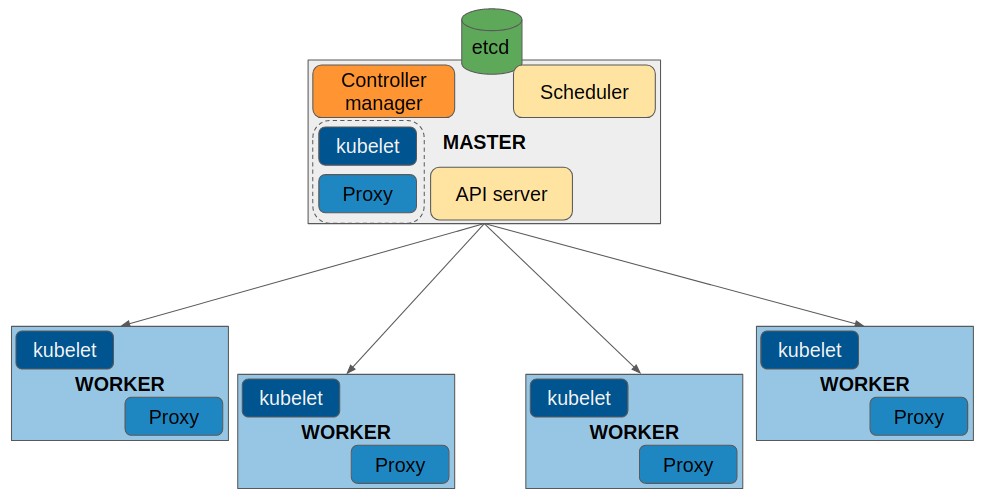
Let’s introduce the Kubernetes components. Masters and workers run different processes, and their number may vary depending on the functionalities provided by each role. Most of these components could be installed as either system services or containers. Here is a list of Kubernetes cluster components:
- kube-apiserver: This is the Kubernetes core, and it exposes the Kubernetes API via HTTP
- kube-scheduler: the scheduler will decide where to run each application components if no node-specific location has been defined
- kube-controller-manager: manage controllers, which are processes that are always watching for a cluster object’s state changes
- etcd: key-value store for all Kubernetes objects’ information and states
- kubelet: core Kubernetes agent component. It will run on any cluster node that is able to execute application workloads
- kube-proxy: This component will manage the workload’s network interactions using operating system packet filtering and routing features. It should run on any worker node (that is, nodes that run workloads).
Objects
Kubernetes objects are persistent entities in the Kubernetes system. Kubernetes uses these entities to represent the state of your cluster.
Key fields: spec, status. When you create an object in Kubernetes, you must provide the object
specthat describes its desired state, as well as some basic information about the object (such as a name). Thestatusdescribes the current state of the object, supplied and updated by the Kubernetes system and its components.Most often, you provide the information to kubectl in a .yaml file. kubectl converts the information to JSON when making the API request.Namespaces: Namespaces provide a scope for names, a way to divide cluster resources between multiple users. To set the namespace for a current request, use the –namespace flag.
Labels are key/value pairs that are attached to objects. Equality- or inequality-based requirements allow filtering by label keys and values. Set-based label requirements allow filtering keys according to a set of values.
Pods
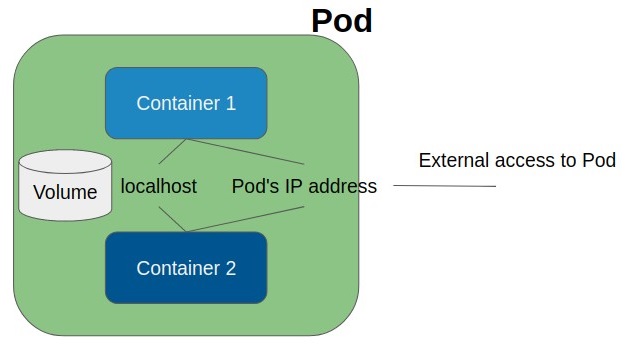
A pod is a group of containers that run together. Pods are the smallest scheduling unit in Kubernetes environments. All of these containers share a network namespace and storage. (Containers within a pod will share the same IP address and can find each other using localhost. Therefore, assigned ports must be unique within pods.)
-
Pods can be used to integrate full application stacks. As pods are the smallest Kubernetes scheduling unit, we scale pods up and down, not containers.
-
Pods allow us to execute a container in order to initialize some special features or properties for another container.
Services
Services are abstract objects for the cluster. They define a logical set of pods that work together to serve an application component. We also use services to publish applications inside and outside a Kubernetes cluster.
-
Headless Services: no load-balancing and no virtual IP.
-
Publishing Services (ServiceTypes):
-
ClusterIP (default): Exposes the Service on a cluster-internal IP. Choosing this value makes the Service only reachable from within the cluster. This is the default ServiceType.
-
NodePort: Exposes the Service on each Node’s IP at a static port (the NodePort). A ClusterIP Service, to which the NodePort Service routes, is automatically created. You’ll be able to contact the NodePort Service, from outside the cluster, by requesting
: . -
LoadBalancer: Exposes the Service externally using a cloud provider’s load balancer. NodePort and ClusterIP Services, to which the external load balancer routes, are automatically created.
-
ExternalName: Maps the Service to the contents of the externalName field (e.g. foo.bar.example.com), by returning a CNAME record with its value. No proxying of any kind is set up.
-
Docker Image
Docker image related information
-
Docker
Docker basic concepts
-
Think in Java
Some interesting words from "Think in Java"
-
Think in Java -- Multithreading
Reading notes for "Think in Java" multithreading part
- Airflow Deployment in AWS
- Cloud Design - Data Management Patterns (4)
- Cloud Design - Data Management Patterns (3)
- Cloud Design - Data Management Patterns (2)
- Cloud Design - Data Management Patterns (1)
- Head First Design Patterns
- Design Data-Intensive Applications
- Container Orchestration
- Docker Image
- Docker