Introduction
In the book “Data Pipelines with Apache Airflow”, many concepts, mechanisms and usages of Airflow are introduced.
Here I would like to share two chapters, which I feel the ideas can be applied to other software and applications.
Pipeline job best practices
- Coding style
- Developers in a team should follow the same style guides, e.g.
- Use checkers to force the style in merge request CI/CD
- Use code formatters before code commits
- Set up some application-specific style conversions
- Preferable to use factory pattern for better code reusability
- Manage configurations
- Use a central place to manage all changable parameters
- Take care of credentials & secrets
- Put lists of variables into YAML/JSON files
- Design tasks
- Group closely-related tasks together
- Use version control and create new jobs for big changes
- A single task should be designed to be:
- idempotent (the task is rerunable, same results in source & destination)
- deterministic (the task is rerunable, same output)
- functional paradigms
- limited resource requirement on local environment (CPU, filesystem)
- Optimize the tasks:
- decouple light and heavy workload into different environments, connect them with async methods
- try to split large dataset into smaller/incremental ones for higher efficiency
- improve task speed by cache intermediate data
- Always add monitoring and alerting
Airflow deployment pattern evolution
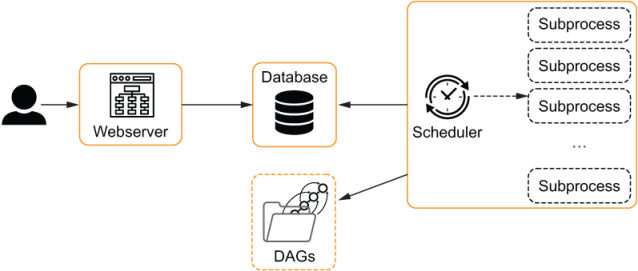
Simple architecure:

+ Use a single worker with multiple process:
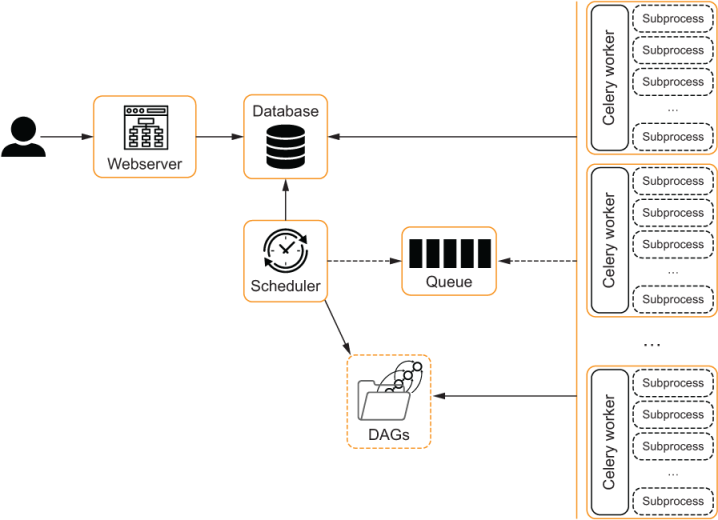
++ Use a queue to manage multiple workers:
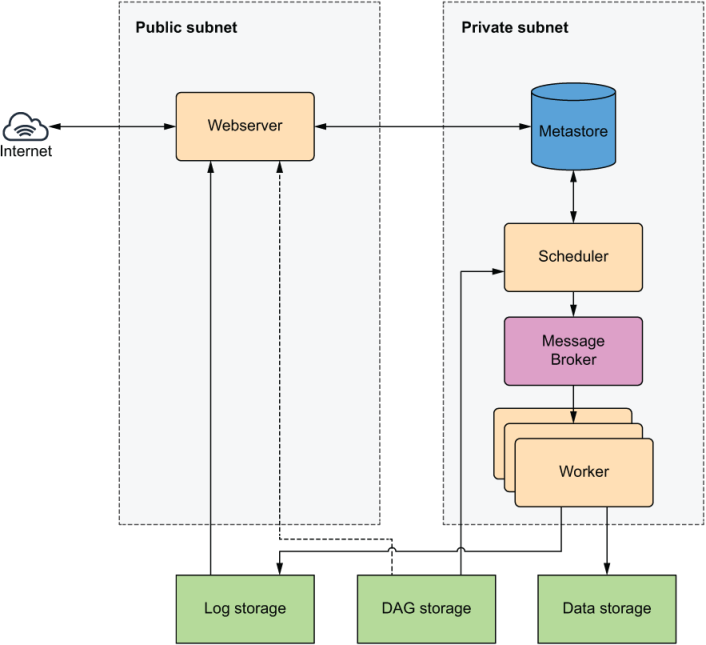
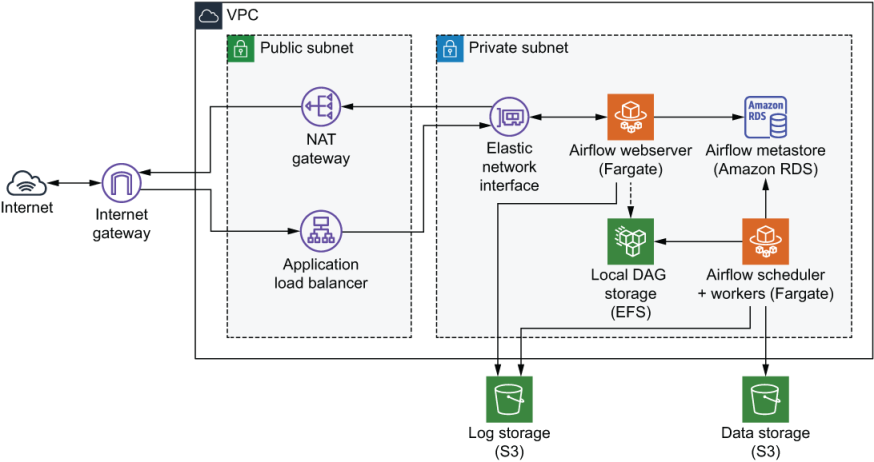
Cloud environment deployment:
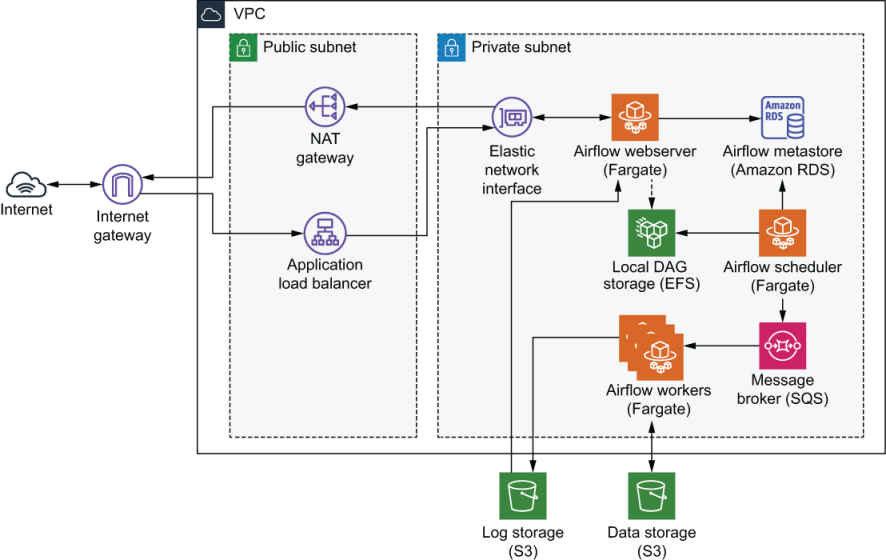
+ Use AWS services:
- NAT gateway + ALB (load balancer): serving as public endpoints
- Eni (network interface): connect public & private subnets
- Fargate: application webserver
- RDS: metastore
- DFS: local shared storage
- S3: log storage & object/data storage
- Fargate: core engine (scheduler and workers)
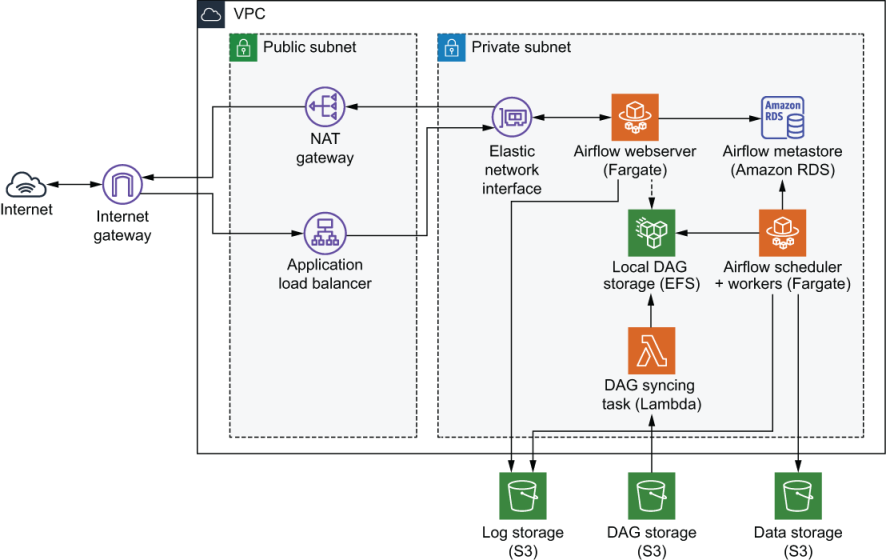
++ Use Lambda for CI/CD
++ Use SQS (queue) to manage workers from scheduler