MapReduce
Components:
- map: (K1, V1) → list(K2, V2)
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { public class Context extends MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { // ... } protected void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException { // ... context.write(KEYOUT key, VALUEOUT value); } } - combiner: (K2, list(V2)) → list(K2, V2)
- reduce: (K2, list(V2)) → list(K3, V3)
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { public class Context extends ReducerContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { // ... } protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context) throws IOException, InterruptedException { // ... context.write(KEYOUT key, VALUEOUT value); } } - partition: (K2, V2) → integer
public class HashPartitioner<K, V> extends Partitioner<K, V> { public int getPartition(K key, V value, int numReduceTasks) { // ... return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } } - driver
public class MinimalMapReduceWithDefaults extends Configured implements Tool { @Override public int run(String[] args) throws Exception { if (args.length != 2) { System.err.printf("Usage: %s [genericOptions] %s\n\n", this.getClass().getSimpleName(), "<input> <output>"); GenericOptionsParser.printGenericCommandUsage(System.err); return null; } Job job = new Job(conf); job.setJarByClass(tool.getClass()); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); if (job == null) { return -1; } job.setInputFormatClass(TextInputFormat.class); job.setMapperClass(Mapper.class); job.setMapOutputKeyClass(LongWritable.class); job.setMapOutputValueClass(Text.class); job.setPartitionerClass(HashPartitioner.class); job.setNumReduceTasks(1); // the number of map tasks is equal to the number of splits that the input is turned into job.setReducerClass(Reducer.class); job.setOutputKeyClass(LongWritable.class); job.setOutputValueClass(Text.class); job.setOutputFormatClass(TextOutputFormat.class); return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { int exitCode = ToolRunner.run(new MinimalMapReduceWithDefaults(), args); System.exit(exitCode); } }
Input Formats
An input split is a chunk of the input that is processed by a single map. Each split is divided into records, and the map processes each record, a key-value pair, in turn.
Input splits are represented by the Java class InputSplit, which has a length in bytes and a set of storage locations, which are just hostname strings. Notice that a split doesn’t contain the input data; it is just a reference to the data.
public abstract class InputSplit {
public abstract long getLength() throws IOException, InterruptedException;
public abstract String[] getLocations() throws IOException,
InterruptedException;
}
public abstract class InputFormat<K, V> {
public abstract List<InputSplit> getSplits(JobContext context)
throws IOException, InterruptedException;
public abstract RecordReader<K, V>
createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException;
}
An InputFormat is responsible for creating the input splits and dividing them into records. The split size is calculated by the following formula: max( minimumSize, min( maximumSize, blockSize ) ).
Here is a hierarchy graph of InputFormat classes:
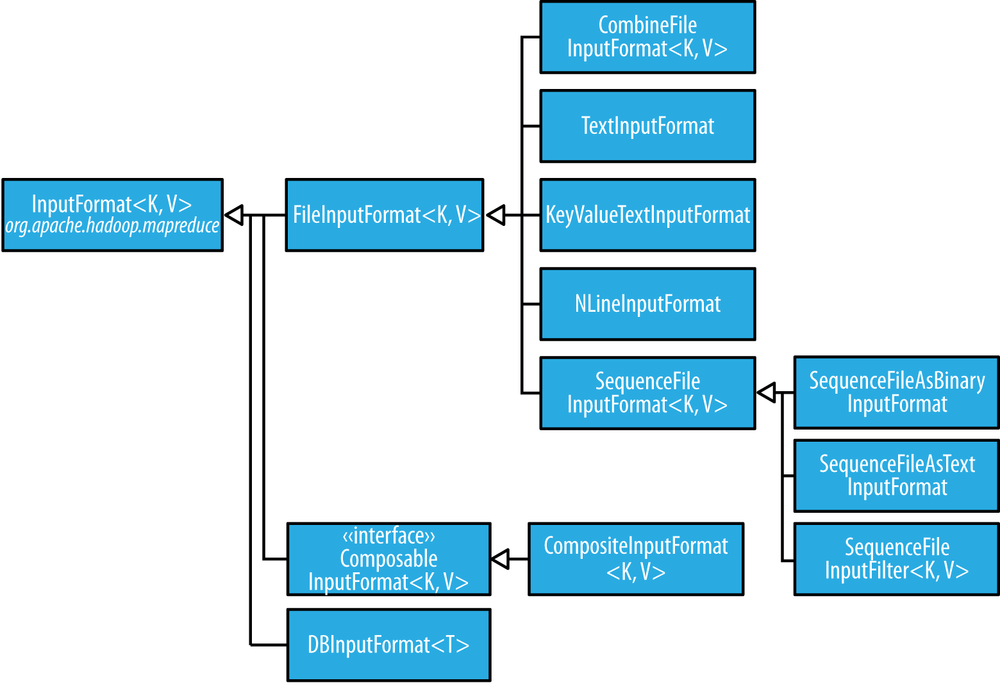
CombineFileInputFormatpacks many files into each split so that each mapper has more to process.- There are a couple of ways to ensure that an existing file is not split. The first (quick-and-dirty) way is to increase the minimum split size to be larger than the largest file in your system. The second is to subclass the concrete subclass of
FileInputFormatthat you want to use, to override theisSplitable()method to return false. TextInputFormatis the defaultInputFormat. Each record is a line of input. The key, aLongWritable, is the byte offset within the file of the beginning of the line. The value is the contents of the line, excluding any line terminators (e.g., newline or carriage return), and is packaged as aTextobject. By setting mapreduce.input.linerecordreader.line.maxlength to a value in bytes that fits in memory (and is comfortably greater than the length of lines in your input data), you ensure that the record reader will skip the (long) corrupt lines without the task failing.- To use data from sequence files as the input to MapReduce, you can use
SequenceFileInputFormat. The keys and values are determined by the sequence file, and you need to make sure that your map input types correspond.
The map task passes the split to the createRecordReader() method on InputFormat to obtain a RecordReader for that split. A RecordReader is little more than an iterator over records, and the map task uses one to generate record key-value pairs, which it passes to the map function.

Output Formats
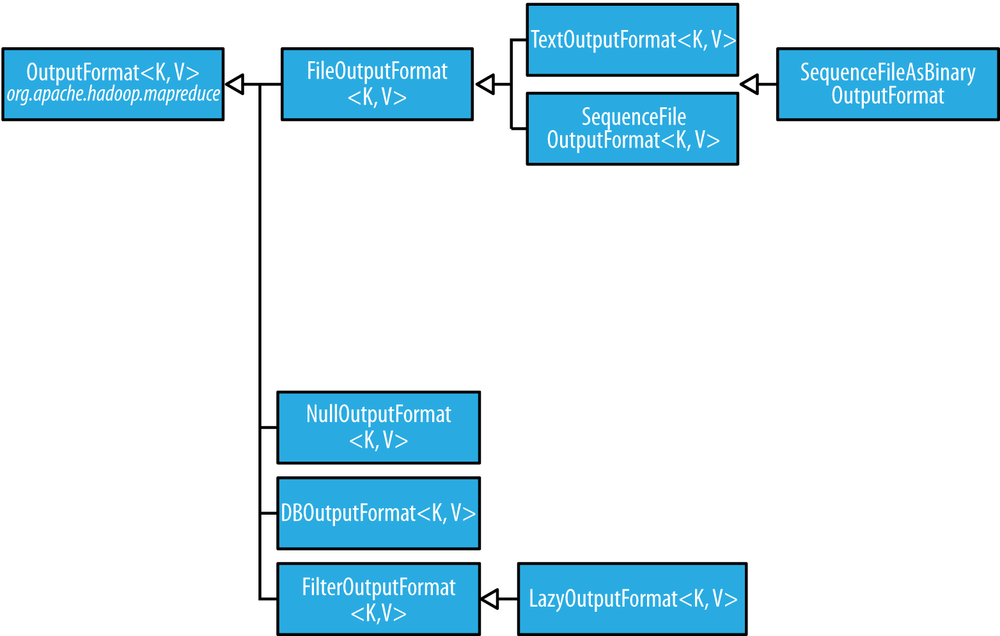
- The default output format,
TextOutputFormat, writes records as lines of text. Its keys and values may be of any type, sinceTextOutputFormatturns them to strings by callingtoString()on them. Each key-value pair is separated by a tab character, although that may be changed using themapreduce.output.textoutputformat.separatorproperty. SequenceFileOutputFormatwrites sequence files for its output. This is a good choice of output if it forms the input to a further MapReduce job, since it is compact and is readily compressed.- Use
MultipleOutputsclass to have more control over the naming of the files or to produce multiple files per reducer.for (Text value : values) { parser.parse(value); String basePath = String.format("%s/%s/part", parser.getStationId(), parser.getYear()); multipleOutputs.write(NullWritable.get(), value, basePath); } LazyOutputFormatis a wrapper output format that ensures that the output file is created only when the first record is emitted for a given partition.
The reduce input keys are guaranteed to be sorted, but the output keys are under the control of the reduce function.
Counters
Counters are a useful channel for gathering statistics about the job: for quality control or for application-level statistics.
Counters are divided into groups, and there are several groups for the built-in counters: MapReduce task counters, Filesystem counters, FileInputFormat counters, FileOutputFormat counters, Job counters. MapReduce also allows user code to define a set of counters, which are then incremented as desired in the mapper or reducer.
Counters are defined by a Java enum, which serves to group related counters. A job may define an arbitrary number of enums, each with an arbitrary number of fields. The name of the enum is the group name, and the enum’s fields are the counter names. Counters are global: the MapReduce framework aggregates them across all maps and reduces to produce a grand total at the end of the job.
Sorting
The ability to sort data is at the heart of MapReduce. By default, MapReduce will sort input records by their keys for each reduce task. The sort order for keys is controlled by a RawComparator, which is found as follows:
- If the property
mapreduce.job.output.key.comparator.classis set, either explicitly or by callingsetSortComparatorClass()on Job, then an instance of that class is used. - Otherwise, keys must be a subclass of
WritableComparable, and the registered comparator for the key class is used. - If there is no registered comparator, then a
RawComparatoris used. TheRawComparatordeserializes the byte streams being compared into objects and delegates to theWritableComparable’scompareTo()method.
These rules reinforce the importance of registering optimized versions of RawComparators for your own custom Writable classes.
Joins
-
Map-side join
A map-side join between large inputs works by performing the join before the data reaches the map function.
Each input dataset must be divided into the same number of partitions, and it must be sorted by the same key (the join key) in each source. All the records for a particular key must reside in the same partition.
You use a
CompositeInputFormatfrom theorg.apache.hadoop.mapreduce.joinpackage to run a map-side join. -
Reduce-side join
A reduce-side join is more general than a map-side join, in that the input datasets don’t have to be structured in any particular way, but it is less efficient because both datasets have to go through the MapReduce shuffle.
The basic idea is that the mapper tags each record with its source and uses the join key as the map output key, so that the records with the same key are brought together in the reducer. See Example
Side Data Distribution
-
You can set arbitrary key-value pairs in the job configuration using the various setter methods on Configuration. This is very useful when you need to pass a small piece of metadata to your tasks.
For arbitrary objects you can either handle the serialization yourself or use Hadoop’s
Stringifierclass. -
Hadoop’s distributed cache mechanism provides a service for copying files and archives to the task nodes in time for the tasks to use them when they run.
When you launch a job, Hadoop copies the files specified by the -files, -archives, and -libjars options to the distributed filesystem (normally HDFS). (If GenericOptionsParser is not being used, then the API in Job can be used to put objects into the distributed cache.)
Then, before a task is run, the node manager copies the files from the distributed filesystem to a local disk—the cache—so the task can access the files. The files are said to be localized at this point. In addition, files specified by -libjars are added to the task’s classpath before it is launched.
The node manager also maintains a reference count for the number of tasks using each file in the cache.