- MapReduce
- Developing a MapReduce application
- Running a MapReduce Application
- Shuffle and Sort
- Task Execution
MapReduce
A MapReduce job is a unit of work that the client wants to be performed, it consists of: the input data, the MapReduce program, and configuration information.
Hadoop runs the job by dividing it into tasks, of which there are two types: map tasks and reduce tasks. The tasks are scheduled using YARN and run on nodes in the cluster.
Hadoop divides the input to a MapReduce job into fixed-size pieces called input splits. Hadoop creates one map task for each split. For most jobs, a good split size tends to be the size of an HDFS block (it is the largest size of input that can be guaranteed to be stored on a single node, to have the data locality optimization).
Also, Hadoop allows the user to specify a combiner function to be run on the map output, and the combiner function’s output forms the input to the reduce function.
Developing a MapReduce application
Steps
- set up and configure the development environment
- write your map and reduce functions, ideally with unit tests to make sure they do what you expect
- write a driver program to run a job, which can run from your IDE using a small subset of the data to check that it is working
- use your IDE’s debugger to find the source of the problem, expand your unit tests to cover this case and improve your mapper or reducer as appropriate to handle such input correctly
- unleash it on a cluster
- expand your tests and alter your mapper or reducer to handle the new cases
- tune first by running through some standard checks for making MapReduce programs faster and then by doing task profiling
Hadoop configuration
An instance of the Configuration class (in org.apache.hadoop.conf package) represents a collection of configuration properties and their values. It can be passed into class with driver.setConf(conf);
Some dependencies:
- For building MapReduce jobs, you only need to have the hadoop-client dependency, which contains all the Hadoop client-side classes needed to interact with HDFS and MapReduce.
- For running unit tests, we use junit.
- For writing MapReduce tests, we use mrunit.
- The hadoop-minicluster library contains the “mini-” clusters that are useful for testing with Hadoop clusters running in a single JVM.
It’s more convenient to implement the Tool interface and run your application with the ToolRunner, which uses GenericOptionsParser internally:
public interface Tool extends Configurable {
int run(String [] args) throws Exception;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MaxTemperatureDriver(), args);
System.exit(exitCode);
}
ToolRunner supports options including -D property=value, -conf filename, …
MRUnit
Test mapper and reducer:
public void testMap() throws IOException, InterruptedException {
// ...
new MapDriver<LongWritable, Text, Text, IntWritable>()
.withMapper(new MaxTemperatureMapper())
.withInput(new LongWritable(0), value)
.withOutput(new Text("1950"), new IntWritable(-11))
.runTest();
// ...
}
public void testMap() throws IOException, InterruptedException {
// ...
new ReduceDriver<Text, IntWritable, Text, IntWritable>()
.withReducer(new MaxTemperatureReducer())
.withInput(new Text("1950"), Arrays.asList(new IntWritable(10), new IntWritable(5)))
.withOutput(new Text("1950"), new IntWritable(10))
.runTest();
// ...
}
Test driver:
public class TestDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output>\n",
getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Job job = new Job(getConf(), "Max temperature");
job.setJarByClass(getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(TestMapper.class);
job.setCombinerClass(TestReducer.class);
job.setReducerClass(TestReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new TestDriver(), args);
System.exit(exitCode);
}
}
Running on a cluster
- Packaging a job
- In a distributed setting, a job’s classes must be packaged into a job JAR file to send to the cluster. Hadoop will search for the JAR on the driver’s classpath that contains the class set in the setJarByClass() method (on JobConf or Job). Your can also use the setJar() method to set an explicit JAR file by its file path (can be either local or HDFS).
- Classpaths include:
- job JAR file
- JAR files contained in the lib directory of the job JAR file and the classes directory
- files added to the distributed cache using the -libjars option or the addFileToClassPath() method
- On the client side, you can force Hadoop to put the user classpath first in the search order by setting the
HADOOP_USER_CLASSPATH_FIRSTenvironment variable to true. For the task classpath, you can setmapreduce.job.user.classpath.firstto true.
- Launching a job
hadoop jar hadoop-examples.jar v2.MaxTemperatureDriver -conf conf/hadoop-cluster.xml input/path main
- Get results
Another way of retrieving the output if it is small is to use the -cat option to print the output files to the console:
hadoop fs -cat max-temp/*
-
Debug a job
There are several ways to debug a job:
- Print statements
- Tasks and task attempts pages
- Unit test to handle malformed data
- Hadoop logs
Workflows
- Use JobControl
-
Use Oozie
Apache Oozie is a system for running workflows of dependent jobs. It is composed of two main parts:
- a workflow engine that stores and runs workflows composed of different types of Hadoop jobs (MapReduce, Pig, Hive, etc.)
- a coordinator engine that runs workflow jobs based on predefined schedules and data availability.
Oozie has been designed to scale, and it can manage the timely execution of thousands of workflows in a Hadoop cluster, each composed of possibly dozens of constituent jobs.
Running a MapReduce Application
At the highest level, there are five independent entities in a MapReduce job:
-
The client, which submits the MapReduce job.
-
The YARN resource manager, which coordinates the allocation of compute resources on the cluster.
-
The YARN node managers, which launch and monitor the compute containers on machines in the cluster.
-
The MapReduce application master, which coordinates the tasks running the MapReduce job. The application master and the MapReduce tasks run in containers that are scheduled by the resource manager and managed by the node managers.
-
The distributed filesystem, which is used for sharing job files between the other entities.
You can run a job with submit() on a Job object, or waitForCompletion().
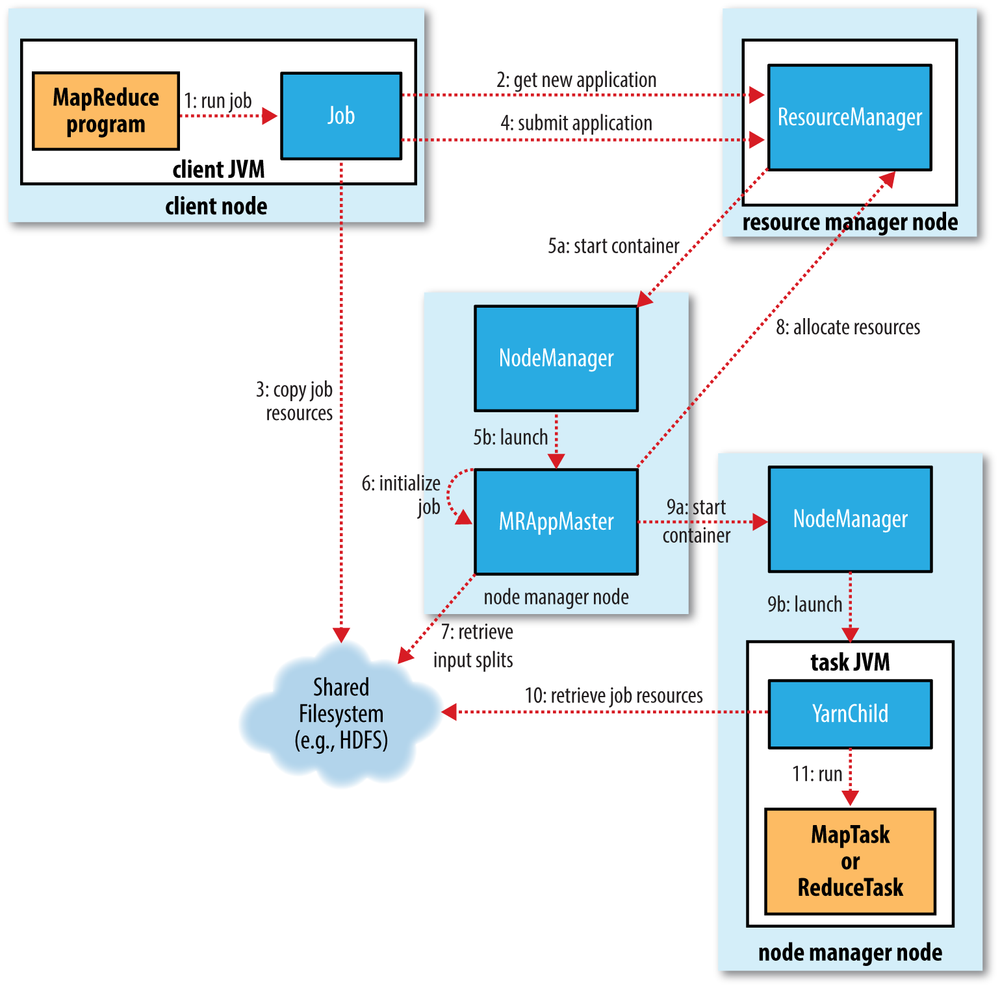
The whole running process is illustrated here:
1. Job Submission
The submit() method on Job creates an internal JobSubmitter instance and calls submitJobInternal() on it (STEP 1). Method waitForCompletion() polls the job’s progress once per second and reports the progress to the console if it has changed since the last report.
When the job completes successfully, the job counters are displayed. Otherwise, the error that caused the job to fail is logged to the console.
Then JobSubmitter does these things:
- Asks the resource manager for a new application ID (STEP 2)
- Checks the output specification of the job, e.g. if the output directory has not been specified or it already exists
- Computes the input splits for the job
- Copies the resources needed to run the job (including the job JAR file, the configuration file, and the computed input splits) to the shared filesystem in a directory named after the job ID (STEP 3). The job JAR is copied with a high replication factor
mapreduce.client.submit.file.replicationwhich default is 10 - Submits the job by calling
submitApplication()on the resource manager (STEP 4)
2. Job Initialization
When the resource manager receives a call to its submitApplication() method, it hands off the request to the YARN scheduler. The scheduler allocates a container, and the resource manager then launches the application master’s process (a Java application whose main class is MRAppMaster) there, under the node manager’s management.
Then the master does these things:
- Initializes the job (STEP 6) by creating a number of bookkeeping objects to receive job progress and completion reports from the tasks later
- Retrieves the input splits computed in the client from the shared filesystem (STEP 7)
- Creates a map task object for each split, as well as a number of reduce task objects determined by the
mapreduce.job.reduces/setNumReduceTasks(), and also given tasks IDs - Choose to run the tasks in the same JVM as itself (uberized) if the job is small (which thresholds are controlled by
mapreduce.job.ubertask.maxmaps,mapreduce.job.ubertask.maxreduces,mapreduce.job.ubertask.maxbytes,mapreduce.job.ubertask.enable) - Calls the
setupJob()method on theOutputCommitterto prepare for job running, e.g. create the final output directory for the job and the temporary working space for the task output
3. Task Assignment
Application master requests containers for all the map and reduce tasks in the job from the resource manager (STEP 8). Requests for map tasks are made first and with higher priority because all the map tasks must complete before the sort phase of the reduce can start.
Requests also specify memory requirements and CPUs for tasks, configurable on a per-job basis (subject to memory settings in YARN and MapReduce) via the following properties: mapreduce.map.memory.mb, mapreduce.reduce.memory.mb, mapreduce.map.cpu.vcores and mapreduce.reduce.cpu.vcores.
Reduce tasks can run anywhere in the cluster, but requests for map tasks have data locality constraints that the scheduler tries to honor: data local optimally and rack local alternatively.
4. Task Execution
Once a task has been assigned resources for a container on a particular node by the resource manager’s scheduler, the application master starts the container by contacting the node manager (STEP 9a, STEP 9b). The task is executed by a Java application whose main class is YarnChild.
First, it localizes the resources that the task needs, including the job configuration and JAR file, and any files from the distributed cache (STEP 10). Then it runs the task (STEP 11).
The YarnChild runs in a dedicated JVM which won’t affect the node manager. The task includes setup action and commit action (e.g. moves the task output from a temporary location to its final location).
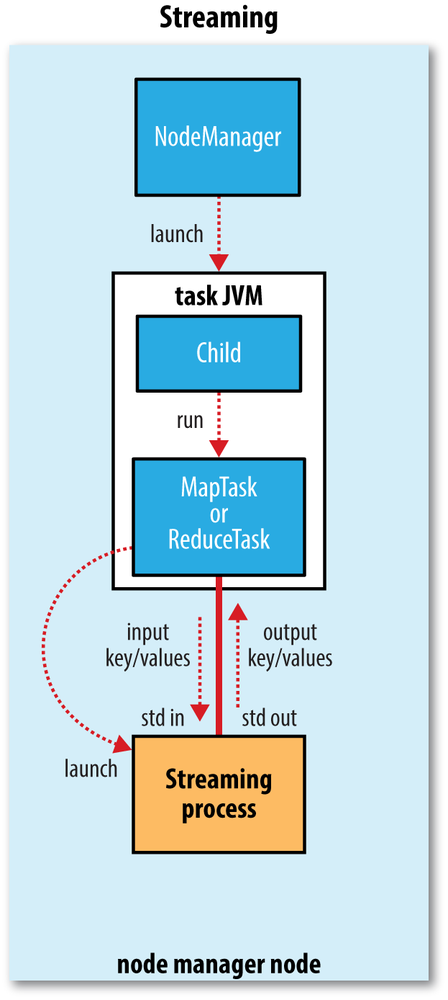
Streaming task is special: it communicates with the process (which may be written in any language) using standard input and output streams.
5. Progress
Progress:
- Progress is not always measurable.
- A task keeps track of its progress. For map tasks, it is the proportion of the processed input data. For reduce tasks, progress is estimated from the three phases of the shuffle (copy, sort, reduce).
- Tasks also have a set of counters that count various events as the task runs.
Communications:
- The child processes in the tasks communicates with its parent application master through the umbilical interface to report progress and status (including counters) every three seconds.
- The client receives the latest status by polling the application master every
mapreduce.client.progressmonitor.pollinterval. Clients can also use Job’s getStatus() method to obtain a JobStatus instance, which contains all of the status information for the job.
6. Job Completion
-
Success: Job statistics and counters are printed to the console. The application master and the task containers clean up their working state. Job information is archived by the job history server.
-
Failure:
-
Task failure
- Task JVM reports the error back to its parent application master and then exits. The container will be cleaned up.
- Streaming process exits with a nonzero exit code.
- The node manager notices that the process has exited (caused by JVM bug or node issue).
- Hanging tasks are marked as failed when application master hasn’t received a progress update for
mapreduce.task.timeout.
When the application master is notified of a task attempt that has failed, it will reschedule execution of the task. It will try to avoid rescheduling the task on a node manager where it has previously failed. The maximum number of attempts is controlled by the
mapreduce.map.maxattemptsandmapreduce.reduce.maxattempts. The maximum percentage of tasks that are allowed to fail without triggering job failure can be set for the job ismapreduce.map.failures.maxpercentandmapreduce.reduce.failures.maxpercent.A task attempt may be killed because it is a speculative duplicate, or because the node manager it was running on failed. It is different from failure.
-
Application master failure
YARN tries running MapReduce application master at most
mapreduce.am.max-attempts, and other YARN application masters at mostyarn.resourcemanager.am.max-attempts.For the MapReduce application master, it will use the job history to recover the state of the tasks that were already run by the (failed) application so they don’t have to be rerun, this is controlled by
yarn.app.mapreduce.am.job.recovery.enable. -
Node manager failure
The resource manager will notice a node manager that has stopped sending heartbeats if it hasn’t received one for
yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms, and remove it from its pool of nodes to schedule containers on.Any task or application master running on the failed node manager will be recovered. Some map tasks that were run and completed successfully on the failed node manager to be rerun because intermediate output residing on the failed node manager’s local filesystem may not be accessible to the reduce task.
Node managers may be blacklisted if the number of failures for the application is high as
mapreduce.job.maxtaskfailures.per.tracker. -
Resource manager failure
When failure of the resource manager happens, neither jobs nor task containers can be launched.
To achieve high availability (HA), it is necessary to run a pair of resource managers in an active-standby configuration. Information about all the running applications is stored in a highly available state store (backed by ZooKeeper or HDFS).
The transition of a resource manager from standby to active is handled by a failover controller. The default failover controller is an automatic one, which uses ZooKeeper leader election to ensure that there is only a single active resource manager at one time. Clients and node managers must be configured to try connecting to each resource manager in a round-robin fashion until they find the active one.
-
Shuffle and Sort
MapReduce makes the guarantee that the input to every reducer is sorted by key. The process by which the system performs the sort—and transfers the map outputs to the reducers as inputs—is known as the shuffle.
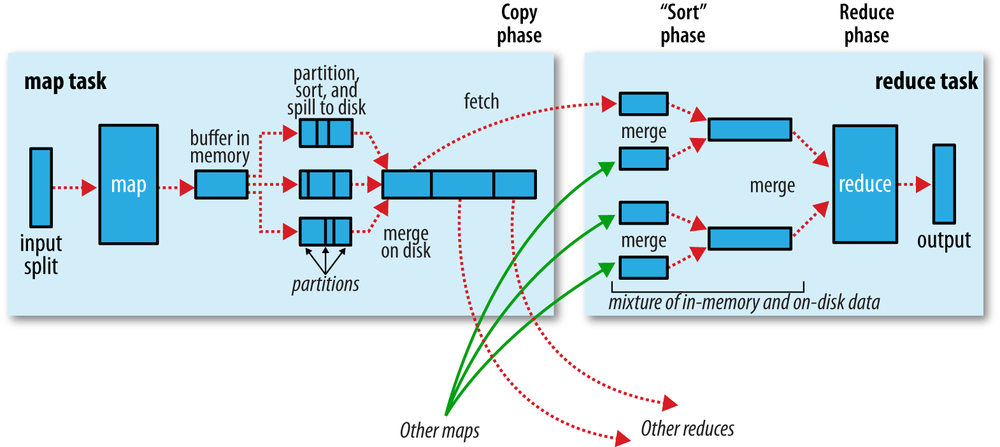
- Map side
- Each map task has a circular memory buffer with size
mapreduce.task.io.sort.mbthat it writes the output to. - When the contents of the buffer reach a certain threshold size
mapreduce.map.sort.spill.percent, a background thread will start to spill the contents. - The thread divides the data into partitions corresponding to the reducers that they will ultimately be sent to. Within each partition, it performs an in-memory sort by key. The combiner function is run on the output of the sort.
- Spills are written in round-robin fashion to a job-specific subdirectory in
mapreduce.cluster.local.dir. Each time the memory buffer reaches the spill threshold, a new spill file is created. (map outputs always get written to local disk) - The spill files are merged into a single partitioned and sorted output file. The maximum number of streams to merge at once is controlled by
mapreduce.task.io.sort.factor. - The combiner is run again if there are
mapreduce.map.combine.minspillsand more spills. - Compress the map output as it is written to disk by setting
mapreduce.map.output.compressand usingmapreduce.map.output.compress.codec. - Files are delected after the job has completed.
- The output file’s partitions are made available to the reducers over HTTP. There are up to
mapreduce.shuffle.max.threadsworker threads used to serve the file partitions.
- Each map task has a circular memory buffer with size
- Reduce side
- The reduce task starts copying their outputs as soon as each map task completes. This is known as the
copy. The reduce task has ` mapreduce.reduce.shuffle.parallelcopies` copier threads to fetch data in parallel. - Map outputs are copied to the reduce task JVM’s memory if they can fit the buffer with
mapreduce.reduce.shuffle.input.buffer.percent, otherwise, they are copied to disk. - When the in-memory buffer reaches
mapreduce.reduce.shuffle.merge.percentor reachesmapreduce.reduce.merge.inmem.threshold, it is merged and spilled to disk. The combiner will be run during the merge. - As the copies accumulate on disk, a background thread merges them into larger, sorted files. During this, data is decompressed in memory.
- When all the map outputs have been copied, the reduce task moves into the
sortphase (which should properly be called the merge phase), which merges the map outputs, maintaining their sort ordering. This is done in rounds and each round mergesmapreduce.task.io.sort.factorfiles. - The final merge can come from a mixture of in-memory and on-disk segments, it is done in the
reducephase. - During the reduce phase, the reduce function is invoked for each key in the sorted output.
- The output of this phase is written directly to the output filesystem, typically HDFS (and the first block replica will be written to the local disk).
- The reduce task starts copying their outputs as soon as each map task completes. This is known as the
- Tuning
- The general principle is to give the shuffle as much memory as possible. It is best to write your map and reduce functions to use as little memory as possible.
- On the map side, the best performance can be obtained by avoiding multiple spills to disk; one is optimal. In particular, you should increase
mapreduce.task.io.sort.mbif you can. - On the reduce side, the best performance is obtained when the intermediate data can reside entirely in memory. If your reduce function has light memory requirements, setting
mapreduce.reduce.merge.inmem.thresholdto 0 andmapreduce.reduce.input.buffer.percentto 1.0. - Increase buffer size by setting
io.file.buffer.size.
Task Execution
-
Properties
In the new API, these properties can be accessed from the context object passed to all methods of the Mapper or Reducer. A task may find its working directory by retrieving
mapreduce.task.output.dirproperty from the job configuration. -
Speculation
The MapReduce model is to break jobs into tasks and run the tasks in parallel to make the overall job execution time smaller than it would be if the tasks ran sequentially. This makes the job execution time sensitive to slow-running tasks. Hadoop tries to detect when a task is running slower than expected and launches another equivalent task as a backup. This is termed speculative execution of tasks, and can be controlled by settings.
The scheduler tracks the progress of all tasks of the same type (map and reduce) in a job, and only launches speculative duplicates for the small proportion that are running significantly slower than the average. When a task completes successfully, any duplicate tasks that are running are killed since they are no longer needed.
-
Commit
Hadoop MapReduce uses a commit protocol to ensure that jobs and tasks either succeed or fail cleanly. The behavior is implemented by the
OutputCommitterwhich is determined by theOutputFormat, via itsgetOutputCommitter()method.The setupJob() method is called before the job is run, and is typically used to perform initialization.
If the job succeeds, the commitJob() method is called, which in the default file-based implementation deletes the temporary working space and creates a hidden empty marker file in the output directory called _SUCCESS to indicate to filesystem clients that the job completed successfully.
If the job did not succeed, abortJob() is called with a state object indicating whether the job failed or was killed and also delete the job’s temporary working space.