Hadoop
Hadoop provides a reliable, scalable platform for storage and analysis.
Data locality, is at the heart of data processing in Hadoop and is the reason for its good performance.
One important system in Hadoop ecosystem is MapReduce, which is fundamentally a batch processing system. This will be introduced in the next post.
Another important system is YARN (Yet Another Resource Negotiator). YARN is a cluster resource management system, which allows any distributed program (not just MapReduce) to run on data in a Hadoop cluster.
HDFS
Filesystem
HDFS is Hadoop Distributed Filesystem, it has the following characteristics:
- High throughput, not low-latency data acesss like HBase
- Very large files, not lots of small files
- Streaming data access patterns, not arbitrary file modifications
- Write-once and read-many-times pattern, not multiple writers
- Running on clusters of commodity hardware
Blocks
HDFS has the concept of a block, but it is a much larger unit—128 MB by default, to minimize the cost of seeks (A quick calculation shows that if the seek time is around 10 ms and the transfer rate is 100 MB/s, to make the seek time 1% of the transfer time, we need to make the block size around 100 MB.) A file in HDFS that is smaller than a single block does not occupy a full block’s worth of underlying storage.
This design bring several benefits:
- cross-disk large files
- seperate metadata and file data
- fault tolerance and availability (replicated at block level)
Use hdfs fsck / -files -blocks to list the blocks that make up each file in the filesystem.
Simplicity is something to strive for in all systems, but it is especially important for a distributed system in which the failure modes are so varied.
Nodes
An HDFS cluster has two types of nodes operating in a master−worker pattern: a namenode (the master) and a number of datanodes (workers).
-
Namenode
The namenode manages the filesystem namespace. It maintains the filesystem tree and the metadata for all the files and directories in the tree. This information is stored persistently on the local disk in the form of two files: the namespace image and the edit log.
It keeps a reference to every file and block in the filesystem in memory. Hadoop 2 allows a cluster to scale by adding namenodes, each of which manages a portion of the filesystem namespace.
Resilient to failure:
- back up the files that make up the persistent state of the filesystem metadata
- Secondary namenode. Despite its name, it does not act as a namenode. Its main role is to periodically merge the namespace image with the edit log to prevent the edit log from becoming too large
High availability The namenode is a single point of failure (SPOF). Hadoop 2 use a pair of namenodes in an active-standby configuration.
-
Datanode
Datanodes are the workhorses of the filesystem. They store and retrieve blocks when they are told to (by clients or the namenode), and they report back to the namenode periodically with lists of blocks that they are storing.
-
HDFS federation
Under federation, each namenode manages a namespace volume, which is made up of the metadata for the namespace, and a block pool containing all the blocks for the files in the namespace.
-
HDFS HA
The namenode is a single point of failure (SPOF). In the implementation of adding support for HDFS high availability (HA), there are a pair of namenodes in an active-standby configuration. They have shared storage, an NFS filer, or a quorum journal manager (QJM).
Hadoop filesystems
Hadoop has an abstract notion of filesystems, of which HDFS is just one implementation. The Java abstract class org.apache.hadoop.fs.FileSystem represents the client interface to a filesystem in Hadoop.
There are several concrete URI scheme: file, hdfs, webhdfs, har, viewfs, ftp, s3a, wasb, swift.
Java API
- a Configuration object
- a FileSystem instance
- a Hadoop Path object
- io stream
Here is an example:
public static void cat(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
IO Flow
-
Read path:
-
Write path:
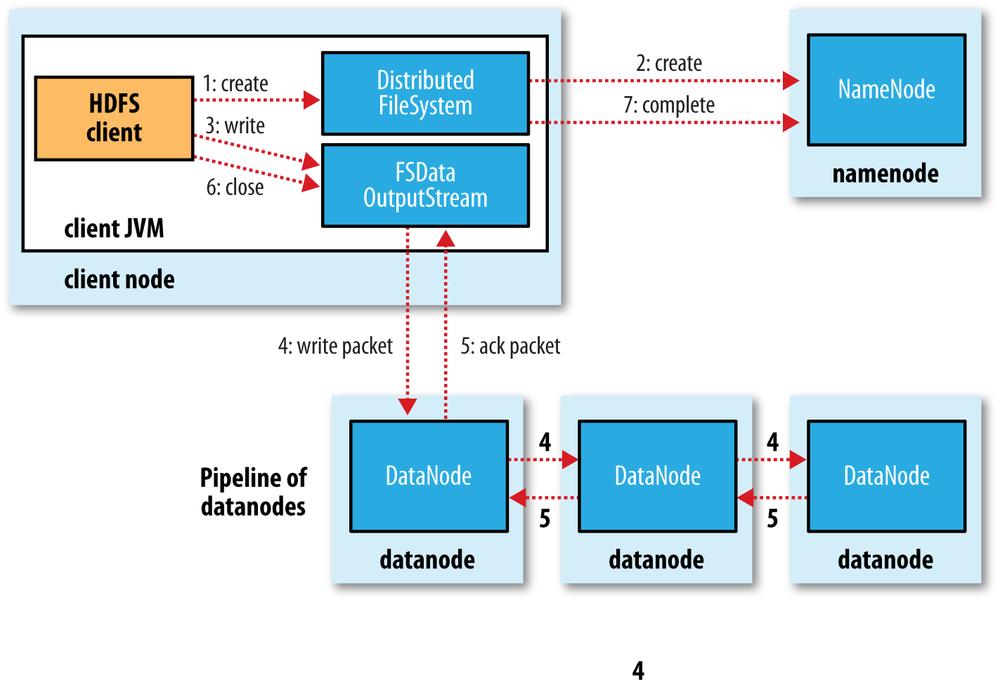
Topology
-
Network Hadoop takes a simple approach in which the network is represented as a tree and the distance between two nodes is the sum of their distances to their closest common ancestor.
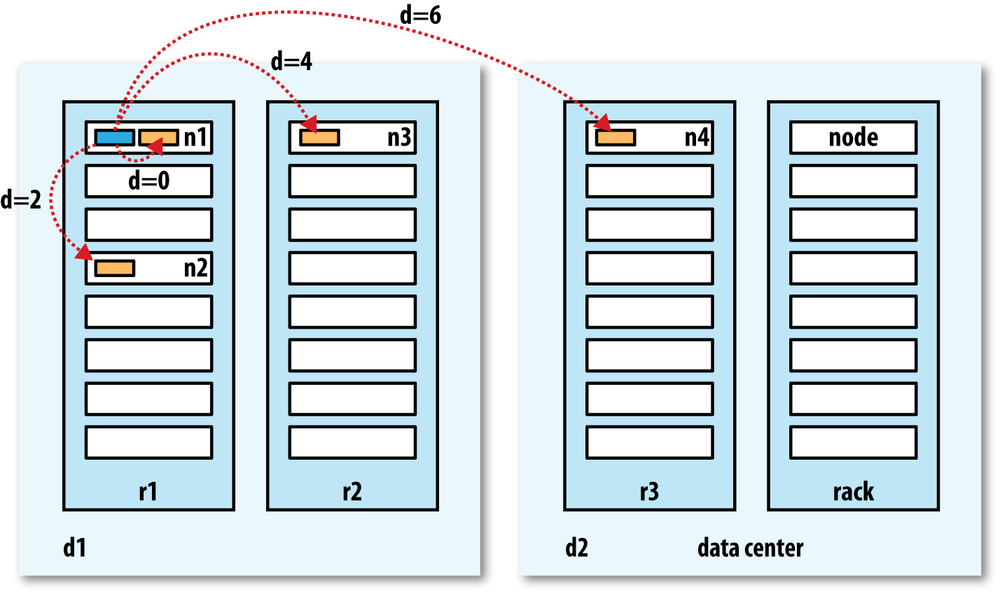
-
Replica placement Hadoop’s default strategy is to place the first replica on the same node as the client (for clients running outside the cluster, a node is chosen at random, although the system tries not to pick nodes that are too full or too busy). The second replica is placed on a different rack from the first (off-rack), chosen at random. The third replica is placed on the same rack as the second, but on a different node chosen at random. Further replicas are placed on random nodes in the cluster, although the system tries to avoid placing too many replicas on the same rack.
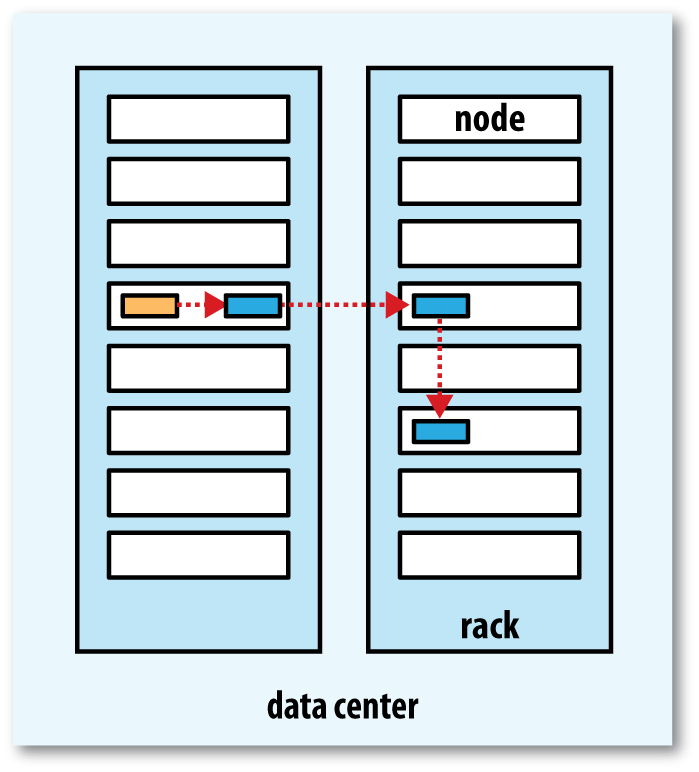
-
Coherency Once more than a block’s worth of data has been written, the first block will be visible to new readers. You should call hflush() at suitable points to avoid data lose when failure occurs, and there is a trade-off between data robustness and throughput.
Tools
-
A CLI
hadoop fs -cmd argumentsis provided for user to do operations in the filesystem. -
distcp a useful program for copying data to and from Hadoop filesystems in parallel. It is implemented as a MapReduce job where the work of copying is done by the maps that run in parallel across the cluster. There are no reducers. Here are two use cases:
- distcp is as an efficient replacement for hadoop fs -cp
- distcp is for transferring data between two HDFS clusters.
IO
Regarding IO, these should be taken into consideration:
- how objects are written and read, since that is central to Hadoop
- need to precisely control how things like connections, timeouts and buffers are handled
Data Integrity
- error-detecting: HDFS uses a more efficient variant called CRC-32C
- HDFS transparently checksums all data written to it and by default verifies checksums when reading data. Datanodes are responsible for verifying the data.
- HDFS stores replicas of blocks, it can “heal” corrupted blocks by copying one of the good replicas to produce a new, uncorrupt replica.
Compression
File compression brings two major benefits: it reduces the space needed to store files, and it speeds up data transfer across the network or to or from disk.
| Compression format | Tool | Algorithm | Filename extension | Splittable | Hadoop CompressionCodec |
|---|---|---|---|---|---|
| DEFLATE | DEFLATE | .deflate | No | org.apache.hadoop.io.compress.DefaultCodec | |
| gzip | gzip | DEFLATE | .gz | No | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | bzip2 | bzip2 | .bz2 | Yes | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | lzop | LZO | .lzo | indexed to support | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | LZ4 | .lz4 | No | org.apache.hadoop.io.compress.Lz4Codec | |
| Snappy | Snappy | .snappy | No | org.apache.hadoop.io.compress.SnappyCodec |
To compress data being written to an output stream, use the createOutputStream(OutputStream out), to decompress data being read from an input stream, call createInputStream(InputStream in) to obtain a CompressionInputStream.
CodecPool allows you to reuse compressors and decompressors, thereby amortizing the cost of creating these objects.
To use compression for map-reduce output: mapreduce.output.fileoutputformat.compress, for map-only output: mapreduce.map.output.compress.
Serialization
Serialization appears in two quite distinct areas of distributed data processing: for interprocess communication and for persistent storage.
An RPC serialization format is compact, fast, extensible and interoperable.
Writable
The default one is org.apache.hadoop.io.serializer.WritableSerialization.
Comparison of types is crucial for MapReduce, where there is a sorting phase during which keys are compared with one another. One optimization that Hadoop provides is the RawComparator extension of Java’s Comparator. For example, to obtain a comparator for IntWritable, we just use: RawComparator<IntWritable> comparator = WritableComparator.get(IntWritable.class);
Here shows the structure of all Writable types.
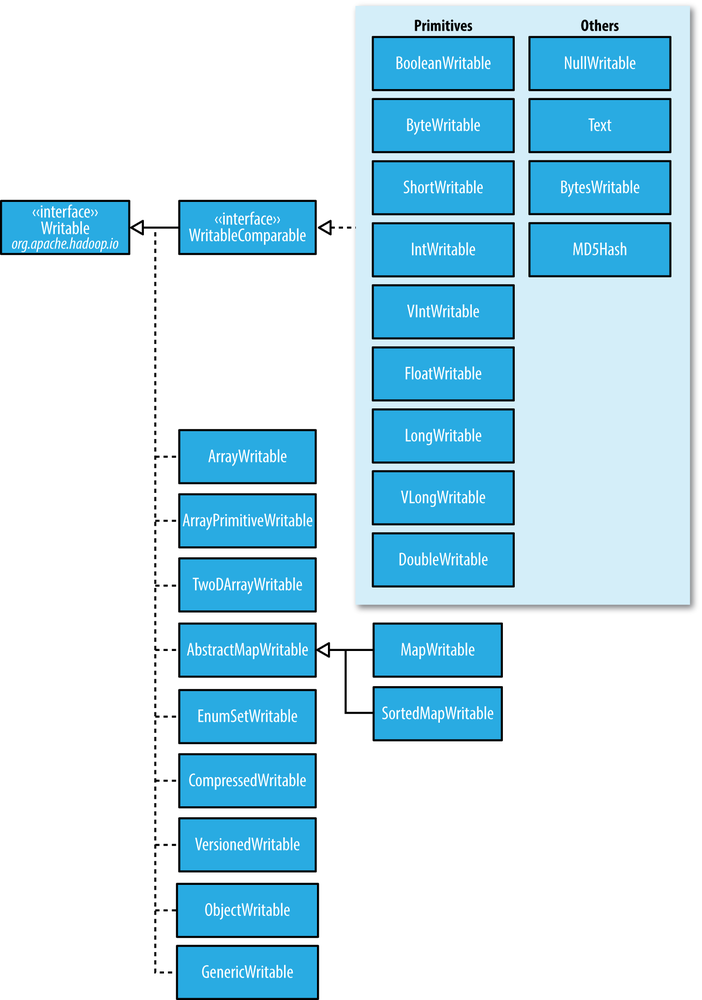
-
Text is a Writable for UTF-8 sequences. It can be thought of as the Writable equivalent of java.lang.String. 1. Indexing for the Text class is in terms of position in the encoded byte sequence. 2. Text is mutable by set(). ! In some situations, the byte array returned by the getBytes() method may be longer than the length returned by getLength().
-
NullWritable is a special type of Writable, as it has a zero-length serialization. No bytes are written to, or read from, the stream. It is used as a placeholder.
- Custom Writable need these functions implemented:
- a default constructor;
- the write() method serializes each object in turn to the output stream, by delegating to the objects themselves;
- similarly, readFields() deserializes the bytes from the input stream by delegating to each object;
- hashCode() used by HashPartitioner
- equals()
- toString(), TextOutputFormat calls toString() on keys and values for their output representation
- compareTo() method that imposes the ordering you would expect
- RawComparator: compare bytes without deserializing objects (faster)
public static class Comparator extends WritableComparator { private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator(); public Comparator() { super(TextPair.class); } @Override public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) { try { int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1); int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2); int cmp = TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2); if (cmp != 0) { return cmp; } return TEXT_COMPARATOR.compare(b1, s1 + firstL1, l1 - firstL1, b2, s2 + firstL2, l2 - firstL2); } catch (IOException e) { throw new IllegalArgumentException(e); } } } static { WritableComparator.define(TextPair.class, new Comparator()); }
- IDL (interface description language): Apache Thrift and Google Protocol Buffers are both popular serialization frameworks, and they are commonly used as a format for persistent binary data. Thrift is used in parts of Hadoop to provide cross-language APIs.
File Formats
SequenceFile
SequenceFile provides a persistent data structure for binary key-value pairs, also work well as containers for smaller files
-
structure
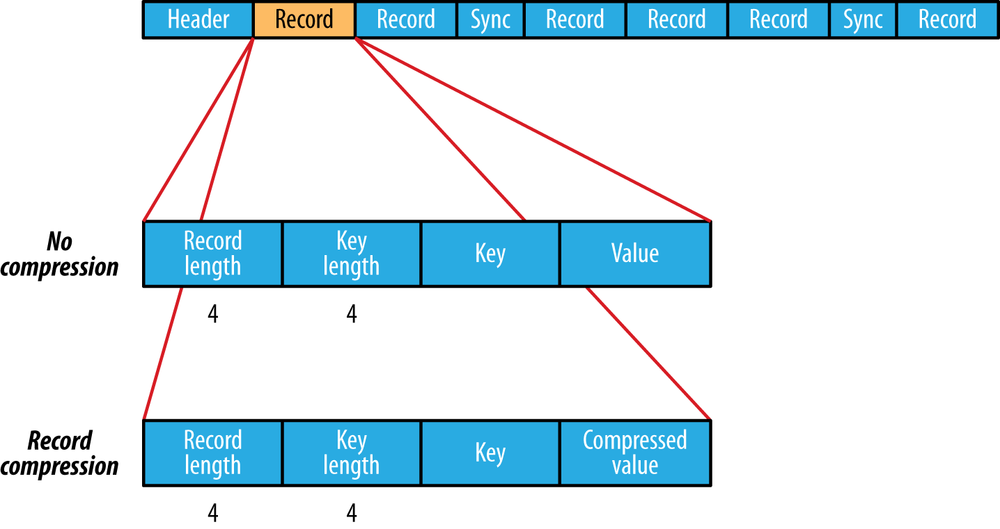
- write and read
SequenceFile.Writer writer = SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass()); writer.append(key, value); ... ... ... SequenceFile.Reader reader = new SequenceFile.Reader(fs, path, conf); Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(), conf); Writable value = (Writable) ReflectionUtils.newInstance(reader.getValueClass(), conf); long position = reader.getPosition(); -
compression: The internal format of the records depends on whether compression is enabled, and if it is, whether it is record compression or block compression.
- MapFile: A MapFile is a sorted SequenceFile with an index to permit lookups by key.
Avro
Apache Avro is a language-neutral data serialization system, code generation is optional in Avro. Avro assumes that the schema is always present—at both read and write time.
Avro schemas are usually written in JSON (https://avro.apache.org/docs/1.8.2/idl.pdf), and data is usually encoded using a binary format (http://avro.apache.org/docs/current/spec.html).
The schema used to read data need not be identical to the schema that was used to write the data, this is the mechanism by which Avro supports schema evolution.
- A default value of a field n schema is used by Avro when there is no such field defined in the records it is reading.
- Another common use of a different reader’s schema is to drop fields in a record, an operation called projection. This is useful when you have records with a large number of fields and you want to read only some of them.
- Another useful technique for evolving Avro schemas is the use of name aliases. Aliases allow you to use different names in the schema used to read the Avro data than in the schema originally used to write the data.
This code section shows how to use Avro format and schema:
Schema.Parser parser = new Schema.Parser();
Schema schema = parser.parse(getClass().getResourceAsStream("StringPair.avsc"));
GenericRecord datum = new GenericData.Record(schema);
datum.put("name", "value"); // add fields
ByteArrayOutputStream out = new ByteArrayOutputStream();
DatumWriter<GenericRecord> writer = new GenericDatumWriter<GenericRecord>(schema);
// stream
Encoder encoder = EncoderFactory.get().binaryEncoder(out, null);
writer.write(datum, encoder);
encoder.flush();
out.close();
// file
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<GenericRecord>(writer);
dataFileWriter.create(schema, file);
dataFileWriter.append(datum);
dataFileWriter.close();
...
...
...
DatumReader<GenericRecord> reader = new GenericDatumReader<GenericRecord>(schema);
// stream
Decoder decoder = DecoderFactory.get().binaryDecoder(out.toByteArray(), null);
GenericRecord result = reader.read(null, decoder);
// file
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(file, reader);
GenericRecord result = dataFileReader.next();
// validate
assertThat("Schema is the same", schema, is(dataFileReader.getSchema()));
assertThat(result.get("name").toString(), is("value"));
...
...
...
// Hadoop
org.apache.avro.mapred package.AvroAsTextInputFormat
org.apache.avro.mapred package.AvroTextOutputFormat
A datafile has a header containing metadata, including the Avro schema and a sync marker, followed by a series of (optionally compressed) blocks containing the serialized Avro objects. Blocks are separated by a sync marker that is unique to the file. Avro datafiles are splittable, which makes them amenable to efficient MapReduce processing.
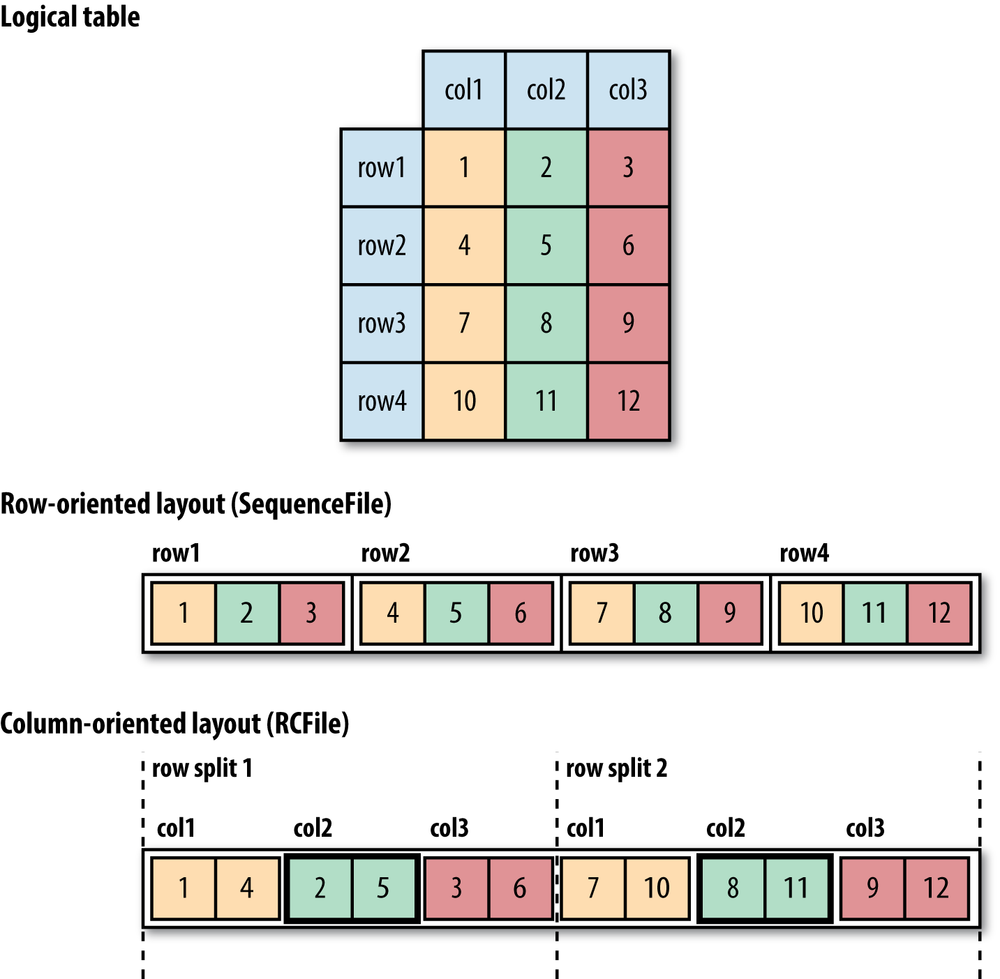
Row-oriented file formats
Sequence files, map files, and Avro datafiles are all row-oriented file formats, which means that the values for each row are stored contiguously in the file. In a column-oriented format, the rows in a file (or, equivalently, a table in Hive) are broken up into row splits, then each split is stored in column-oriented fashion.
-
Pro: A column-oriented layout permits columns that are not accessed in a query to be skipped.
-
Con: Column-oriented formats need more memory for reading and writing, and not suited to streaming writes.
YARN
Users write to higher-level APIs provided by distributed computing frameworks, which themselves are built on YARN and hide the resource management details from the user. Some distributed computing frameworks (MapReduce, Spark, and so on) running as YARN applications on the cluster compute layer (YARN) and the cluster storage layer (HDFS and HBase).
This graph shows the steps:
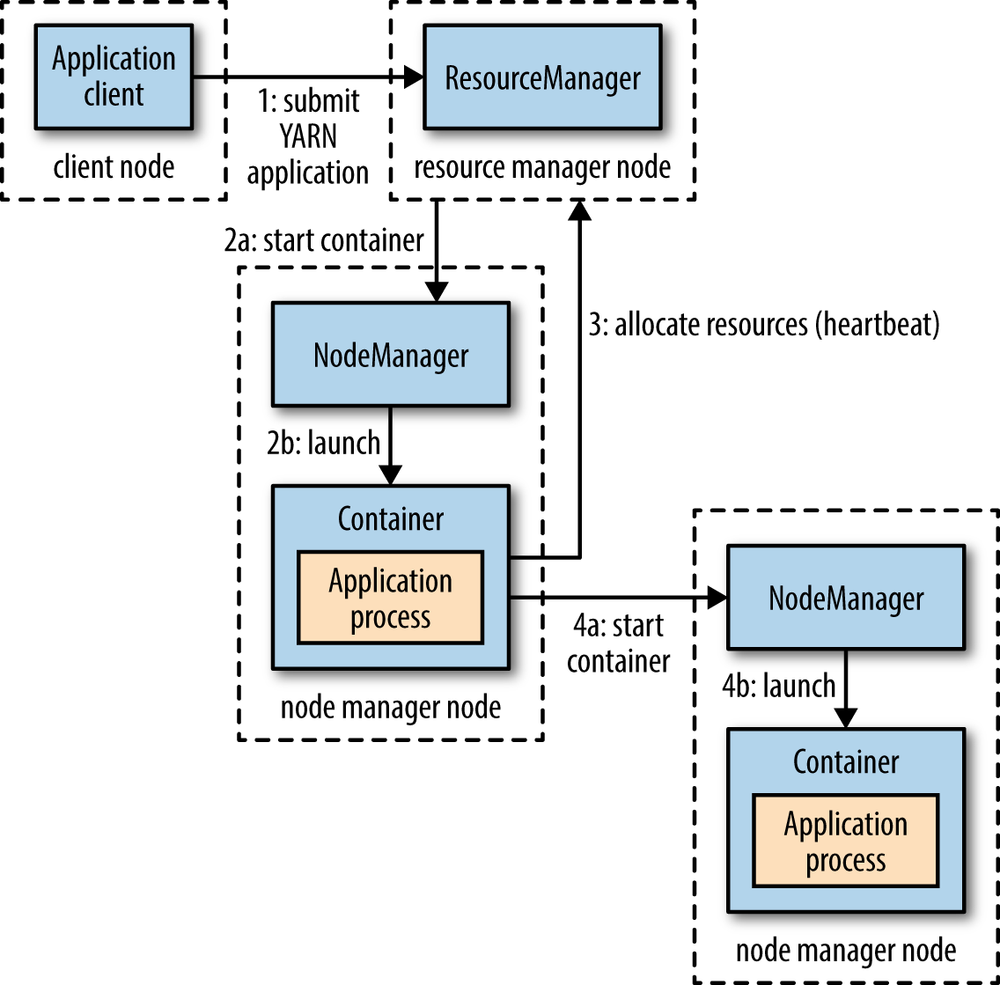
There are several flexible models:
- YARN allows an application to specify locality constraints for the containers it is requesting.
- An application can make all of its requests up front, or it can take a more dynamic approach whereby it requests more resources dynamically to meet the changing needs of the application.
- One application per user job (e.g. MapReduce), or to one application per workflow or user session of (possibly unrelated) jobs (e.g. Spark), or a long-running application that is shared by different users (e.g. Impala)
Also, different scheduler can be set:
- FIFO
- Capacity (a queue hierarchy, the queue name should be the last part of the hierarchical name)
- Fair Schedulers (uses a rules-based system to determine which queue an application is placed in, supports preemption)