Cassandra architecture
Topology
The topology of a cluster, and how nodes interact in a peer-to-peer design to maintain the health of the cluster and exchange data, using techniques like gossip, anti-entropy, and hinted handoff.
-
Gossip
Cassandra uses a gossip protocol that allows each node to keep track of state information about the other nodes in the cluster. The gossiper runs every second on a timer. The term “gossip protocol” was originally coined in 1987 by Alan Demers.
org.apache.cassandra.gms.Gossiper
Cassandra has robust support for failure detection, as specified by a popular algorithm for distributed computing called Phi Accrual Failure Detection implemented by Hayashibara et al.. Basically, Phi is calculated with: \(\phi = -log_{10}(1 - F(timeSinceLastHeartbeat))\) The failure monitoring system outputs a continuous level of “suspicion” regarding how confident it is that a node has failed, rather than a boolean status.
org.apache.cassandra.gms.FailureDetector
-
Hinted handoff
Hinted handoff is used in Amazon’s Dynamo and is familiar to those who are aware of the concept of guaranteed delivery in messaging systems such as the Java Message Service (JMS).
org.apache.cassandra.db.HintedHandOffManager
-
Snitch
The job of a snitch is to determine relative host proximity for each node in a cluster, which is used to determine which nodes to read and write from. The role of the snitch is to help identify the replica that will return the fastest, and this is the replica which is queried for the full data. There are several different classes.
org.apache.cassandra.locator
The “badness threshold” is a configurable parameter that determines how much worse a preferred node must perform than the best-performing node in order to lose its preferential status.
-
Nodes ring
Cassandra represents the data managed by a cluster as a ring. Each node in the ring is assigned one or more ranges of data described by a token, which determines its position in the ring. A token is a 64-bit integer ID used to identify each partition.
Each physical node is then assigned multiple tokens. By default, each node will be assigned 256 of these tokens, meaning that it contains 256 virtual nodes. You can increase the number of vnodes by setting the num_tokens property in the
cassandra.yamlfile.A partitioner, then, is a hash function for computing the token of a partition key. Each row of data is distributed within the ring according to the value of the partition key token. The default partitioner is Murmur3 Partitioner.
org.apache.cassandra.dht package (DHT stands for “distributed hash table”)
-
Read
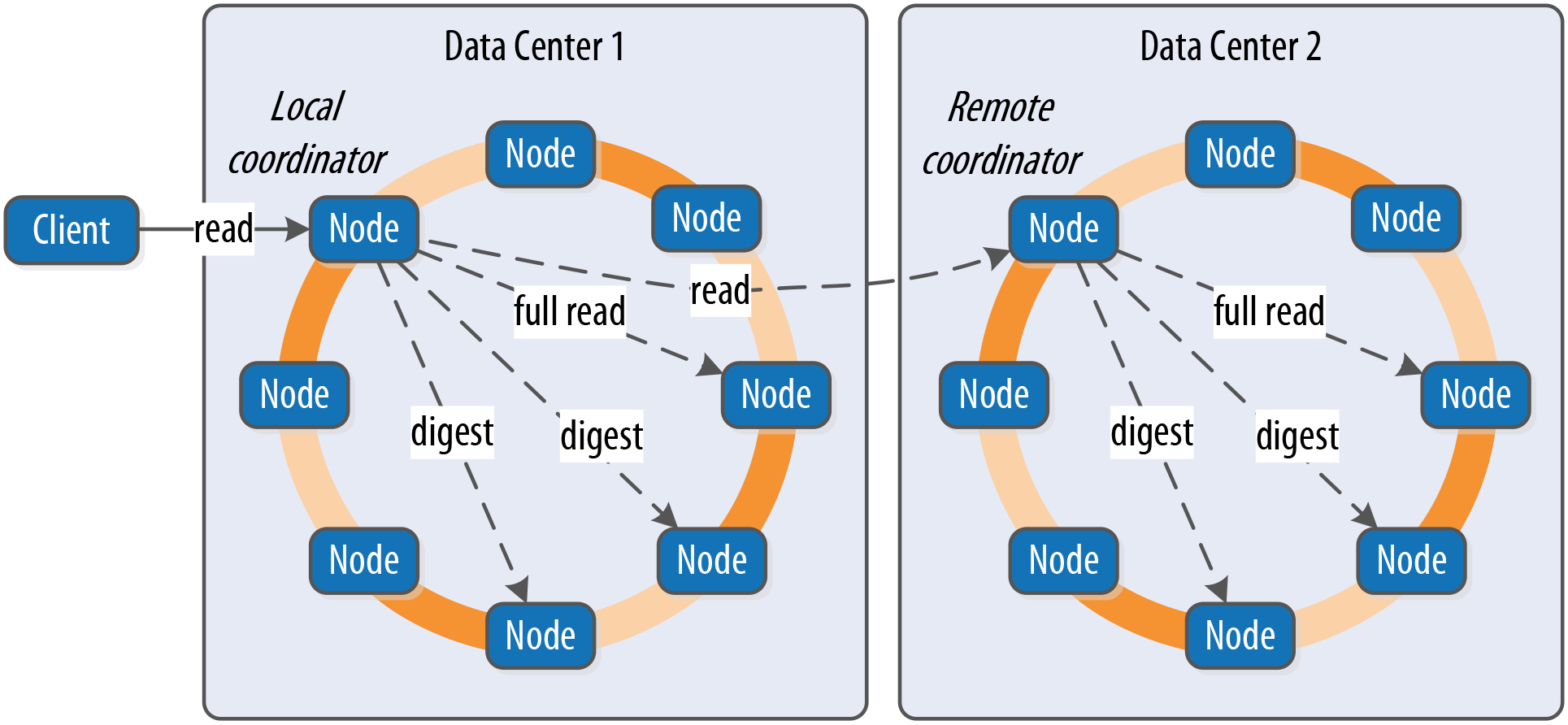
-
Write
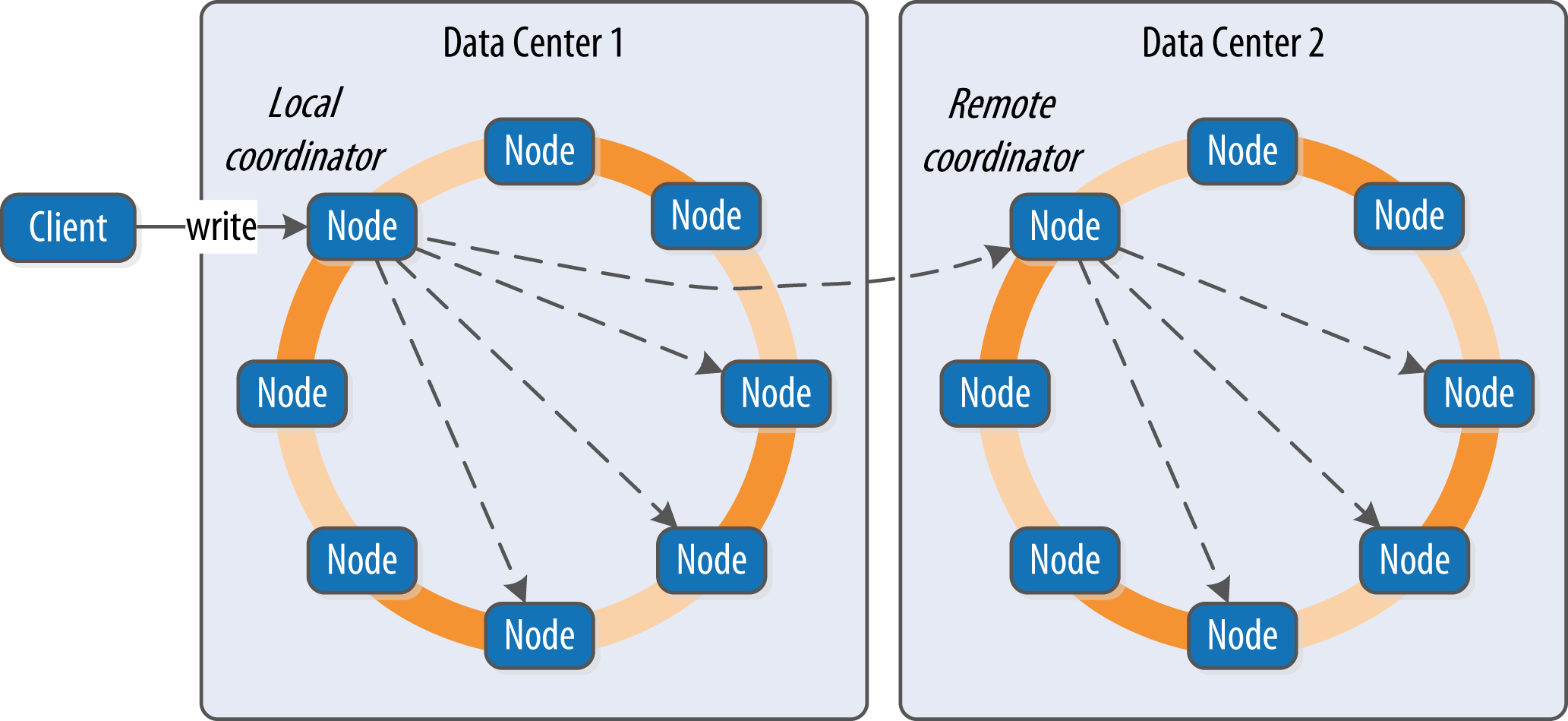
-
Data quality
Architecture techniques Cassandra uses to support reading, writing, and deleting data, and examine how these choices affect architectural considerations such as scalability, durability, availability, manageability, and more.
-
Replica
For determining replica placement, Cassandra implements the Gang of Four (the authors of the book “Design Patterns: Elements of Reusable Object-Oriented Software”, Erich Gamma, Richard Helm, Ralph Johnson and John Vlissides) Strategy pattern (the strategy pattern is used to create an interchangeable family of algorithms from which the required process is chosen at run-time.).
org.apache.cassandra.locator.AbstractReplicationStrategy
- Replica synchronization is supported via two different modes known as read repair and anti-entropy repair. Anti-entropy (sometimes called manual repair) is a manually initiated operation performed with
nodetoolon nodes as part of a regular maintenance process. This protocols work by comparing replicas of data and reconciling differences observed between the replicas.
- Replica synchronization is supported via two different modes known as read repair and anti-entropy repair. Anti-entropy (sometimes called manual repair) is a manually initiated operation performed with
-
Consistency
You specify a consistency level on each read or write query that indicates how much consistency you require. A higher consistency level means that more nodes need to respond to a read or write query, giving you more assurance that the values present on each replica are the same.
Consistency level Implication for write Implication for read ANY Ensure that the value is written to a minimum of one replica node before returning to the client, allowing hints to count as a write. it allows a hint to count as a successful write. ONE, TWO, THREE Ensure that the value is written to the commit log and memtable of at least one, two, or three nodes before returning to the client. Immediately return the record held by the first node(s) that respond to the query. A background thread is created to check that record against the same record on other replicas. If any are out of date, a read repair is then performed to sync them all to the most recent value. LOCAL_ONE Similar to ONE, with the additional requirement that the responding node is in the local data center. Same QUORUM Ensure that the write was received by at least a majority of replicas ((replication factor / 2) + 1). Query all nodes. Once a majority of replicas ((replication factor / 2) + 1) respond, return to the client the value with the most recent,timestamp. Then, if necessary, perform a read repair in the background,on all remaining replicas. LOCAL_QUORUM Similar to QUORUM, where the responding nodes are in the local data center. Same EACH_QUORUM Ensure that a QUORUM of nodes respond in each data center. Same ALL Ensure that the number of nodes specified by replication factor received the write before returning to the client. If even one replica is unresponsive to the write operation, fail the operation. Same -
using QUORUM for writes and ONE for reads doesn’t guarantee strong consistency
-
If the client specifies a weak consistency level (such as ONE), then Cassandra may return an old-date value. Then when the read repair is performed in the background after value returning to the client (merged data), data in each of the replicas could be replace by the old-written but latest-return one.
-
-
Transaction
The database is always writable, and within a column family, writes are always atomic
Cassandra supports a lightweight transaction (or “LWT”) mechanism that provides linearizable consistency. Cassandra’s LWT implementation is based on Paxos. Paxos is a consensus algorithm that allows distributed peer nodes to agree on a proposal, without requiring a master to coordinate a transaction. You can read the Lamport’s paper, and a related post. There is another post about the Byzantine Generals Problem. It is a quite interesting problem talking about decision in a decentralized situation.
There is also a consistency level ( SERIAL / LOCAL_SERIAL ) for Paxos phase of the write.
SEDA
Cassandra’s design was influenced by Staged Event-Driven Architecture (SEDA). SEDA is a general architecture for highly concurrent Internet services, originally proposed in a 2001 paper called “SEDA: An Architecture for Well-Conditioned, Scalable Internet Services” by Matt Welsh, David Culler, and Eric Brewer (who you might recall from our discussion of the CAP theorem). You can read the original SEDA paper.
Data storage
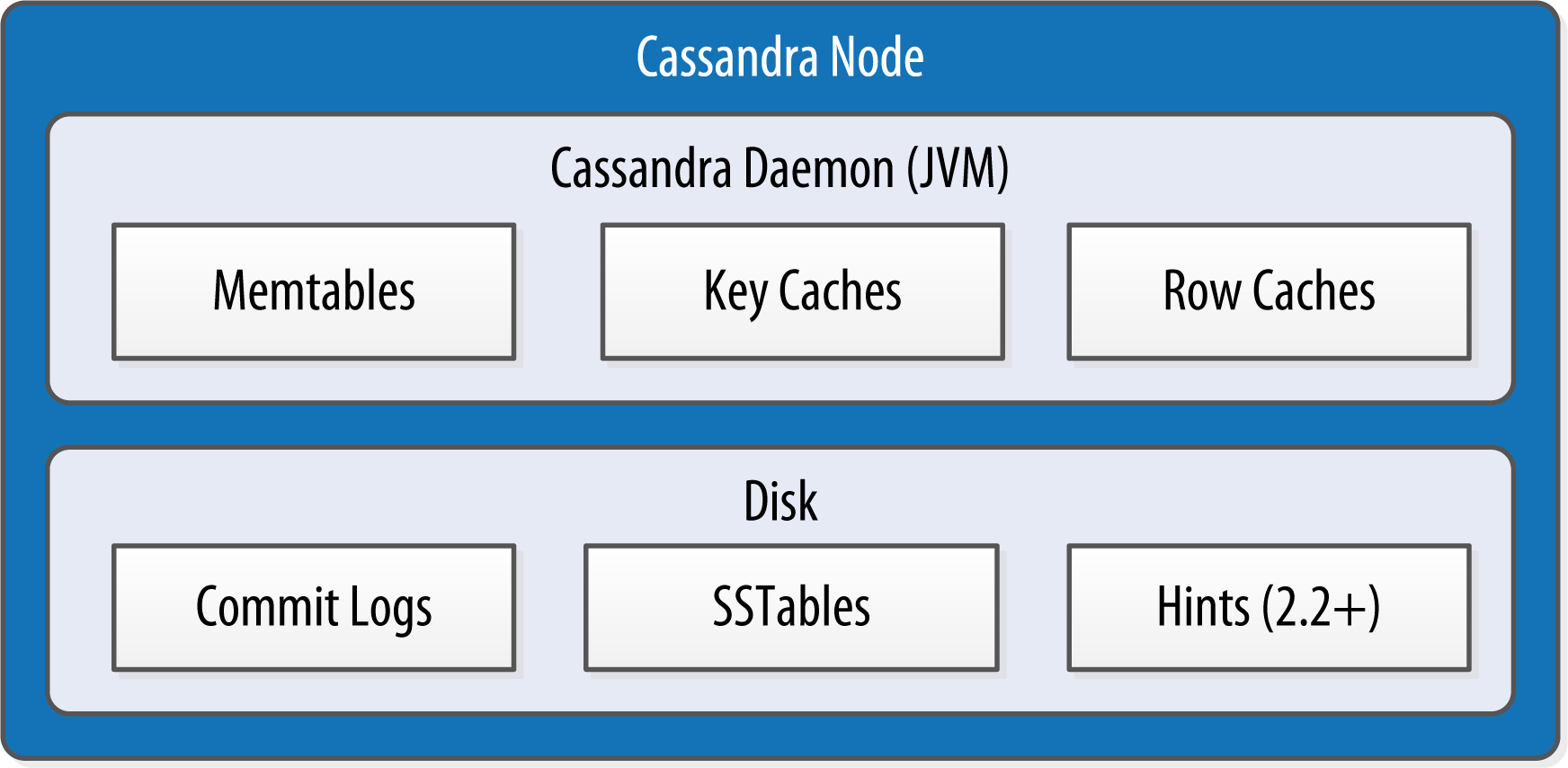
-
The commit log is a crash-recovery mechanism that supports Cassandra’s durability goals. A write will not count as successful until it’s written to the commit log.
The durable_writes property allows you to bypass writing to the commit log for the keyspace. This value defaults to true, meaning that the commit log will be updated on modifications. Setting the value to false increases the speed of writes, but also has the risk of losing data if the node goes down before the data is flushed from memtables into SSTables.
- The memtable is a memory-resident data structure. Each memtable contains data for a specific table. Cassandra 2.1 have moved the majority of memtable data to native memory. The on-heap and off-heap size can be set in
cassandra.yamlorg.apache.cassandra.db.Memtable
-
When the number of objects stored in the memtable reaches a threshold, the contents of the memtable are flushed to disk in a file called an SSTable. A new memtable is then created. This flushing is a non-blocking operation.
-
The idea that “SSTable” is a compaction of “Sorted String Table” is somewhat inaccurate for Cassandra, because the data is not stored as strings on disk. The SSTable is a concept borrowed from Google’s Bigtable. Once a memtable is flushed to disk as an SSTable, it is immutable and cannot be changed by the application. All writes are sequential, which is the primary reason that writes perform so well in Cassandra. all writes are append operations.
-
Bloom filter
Each SSTable also has an associated Bloom filter. Bloom filters work by mapping the values in a data set into a bit array and condensing a larger data set into a digest string using a hash function. It acts as a cache since it may return false positive matches but never return false negative matches, this false positive chance is tuneable per table.
org.apache.cassandra.utils.BloomFilter
-
Tombstone - Delete
When you execute a delete operation, the data is not immediately deleted. Instead, it’s treated as an update operation that places a tombstone on the value. A tombstone is a deletion marker that is required to suppress older data in SSTables until compaction can run. A related setting called Garbage Collection Grace Seconds, which is the amount of time that the server will wait to garbage-collect a tombstone. By default, it’s set to 10 days.
-
Compaction
Compaction is the process of freeing up space by merging large accumulated datafiles. During compaction, the data in SSTables is merged: the keys are merged, columns are combined, tombstones are discarded, and a new index is created. On compaction, the merged data is sorted, a new index is created over the sorted data,
org.apache.cassandra.db.compaction.CompactionManager
Running nodetool repair causes Cassandra to execute a major compaction. During a major compaction, the server initiates a TreeRequest/TreeReponse conversation to exchange Merkle trees with neighboring nodes.
A Merkle tree, named for its inventor, Ralph Merkle, is also known as a “hash tree.” It’s a data structure represented as a binary tree, and it’s useful because it summarizes in short form the data in a larger data set. In a hash tree, the leaves are the data blocks (typically files on a filesystem) to be summarized. Every parent node in the tree is a hash of its direct child node, which tightly compacts the summary.
org.apache.cassandra.utils.MerkleTree
-
-
Cache
Cassandra saves its caches to disk periodically in order to warm them up more quickly on a node restart.
-
The key cache stores a map of partition keys to row index entries, facilitating faster read access (offset of the partition key in the SSTable) into SSTables stored on disk. The key cache is stored on the JVM heap.
-
The row cache caches entire rows and can greatly speed up read access for frequently accessed rows, at the cost of more memory usage. The row cache is stored in off-heap memory. The row cache caches a configurable number of rows per partition. If you are using a row cache for a given table, you will not need to use a key cache on it as well.
ALTER TABLE hotels WITH caching = { 'keys' : 'NONE', 'rows_per_partition' : '200' }; -
The counter cache was added in the 2.1 release to improve counter performance by reducing lock contention for the most frequently accessed counters.
-
Strategy
Your caching strategy should therefore be tuned in accordance with a few factors:
- Consider your queries, and use the cache type that best fits your queries.
- Consider the ratio of your heap size to your cache size, and do not allow the cache to overwhelm your heap.
- Consider the size of your rows against the size of your keys. Typically keys will be much smaller than entire rows.
-
Read and write
-
Read
-
Path
Detailed path from Michael Edge
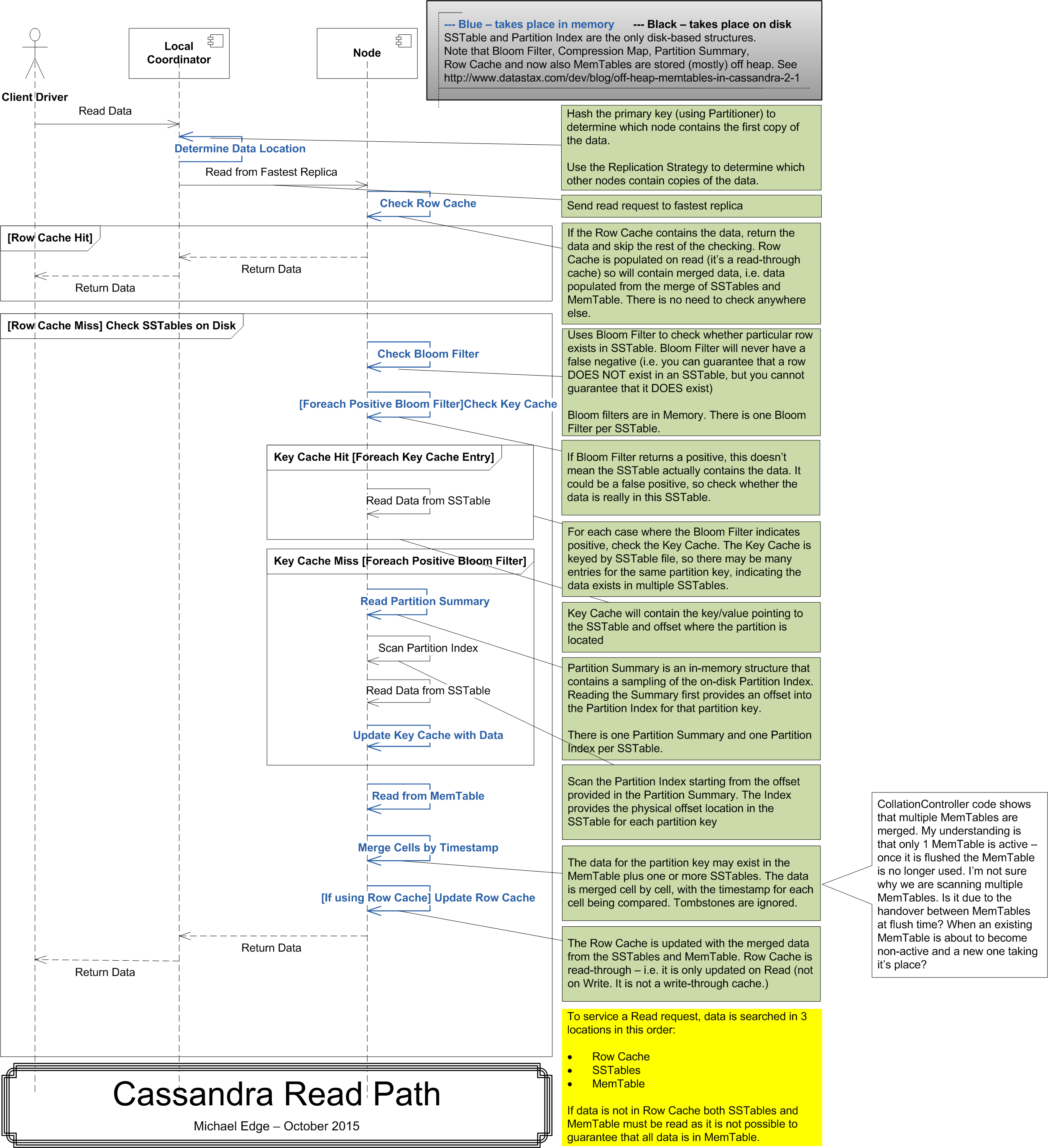
-
-
Write
-
Path
Detailed path from Michael Edge

-
Batch
Cassandra’s batches are sometimes referred to as atomic batches or logged batches. Cassandra’s batches are a good fit for use cases such as making multiple updates to a single partition, or keeping multiple tables in sync. Batches actually decrease performance and can cause garbage collection pressure.
-
Some service parts
| Class | Key feature |
|---|---|
| org.apache.cassandra.service | It includes the typical life cycle operations that you might expect: start, stop, activate, deactivate, and destroy. |
| org.apache.cassandra.service.EmbeddedCassandraService | In-memory Cassandra instance for unit testing programs. |
| org.apache.cassandra.db | The main entry point is the ColumnFamilyStore class, which manages all aspects of table storage, including commit logs, memtables, SSTables, and indexes. |
| org.apache.cassandra.streaming.StreamManager | Streaming is Cassandra’s optimized way of sending sections of SSTable files from one node to another via a persistent TCP connection |
| org.apache.cassandra.transport | The CQL Native Protocol is the binary protocol used by clients to communicate with Cassandra |
| org.apache.cassandra.service.ActiveRepairService | Repair |
| org.apache.cassandra.service.CachingService | Caching |
| org.apache.cassandra.service.MigrationManager | Migration |
| org.apache.cassandra.db.view.MaterializedViewManager | Materialized views |
| org.apache.cassandra.db.index.SecondaryIndexManager | Secondary indexes |
| org.apache.cassandra.auth.CassandraRoleManager | Authorization |
Set up
-
MBeans
Many classes in Cassandra are exposed as MBeans via the Java Management Extension (JMX) in order to report status and metrics, and in some cases to allow configuration and control of their activities.
-
cassandra.yamlConfigure a cluster. See detailed keys.
The key values in configuring a cluster are the cluster name, the partitioner, the snitch, and the seed nodes.
-
cluster name
You can manage clusters with ccm
-
partitioner
To specify how partition keys should be sorted. OPP isn’t more efficient for range queries than random partitioning, using OPP means in practice that your operations team needed to manually rebalance nodes more frequently using nodetool loadbalance or move operations.
-
seed nodes
A seed node is used as a contact point for other nodes. The seed nodes are not strictly required to be exactly the same for every node across the cluster, but it is a good idea to do so.
-
-
conf/cassandra.env.shThis file contains settings to configure the JVM version (if multiple versions are available on your system), heap size, and other JVM options.
-
DataStax Java driver
Java client to interact with Cassandra. See documentations and guides.
-
Other tools
- nodetool
- DataStax OpsCenter
- Netflix Priam