Think different!
Albert Einstein said, if at first the idea is not absurd, then there is no hope for it.
Henry Ford said, if I had asked people what they wanted, they would have said faster horses.
These two sentences are quoted by the author when he talks about how NoSQL solutions comes. With similar design and improved implementation, what you may get is only better performance. Only thinking different can bring really good ideas for the problems that old solutions are unable to handle.
Some knowledge points
There are three main kinds of databases – IMS, RDBM, NoSQL. They each build on prior art, they each attempt to solve certain problems, and so they’re each good at certain things—and less good at others. They each coexist, even now.
-
IMS
IBM designed the IMS with Rockwell and Caterpillar starting in 1966 for the Apollo program, where it was used to inventory the very large bill of materials (BOM) for the Saturn V moon rocket and Apollo space vehicle. IMS uses a hierarchical model. (From Wikipedia)
-
RDBM
RDBM use a relational model. It is the basis for SQL. In Codd’s paper, E. F. Codd, 1970, he proposed twelve rules.
RDBM and SQL support transactions. A transaction is “a transformation of state” that has the ACID properties. ACID is an acronym for Atomic, Consistent, Isolated, Durable.
The two-phase commit protocol (2PC) is a type of atomic commitment protocol (ACP) used in distributed systems. They are commit-request/voting phase and commit phase. Gregor Hohpe, a Google architect, wrote a wonderful and often cited blog entry called “Starbucks Does Not Use Two-Phase Commit.”
-
NoSQL
There is a website listing all NoSQL databases by types.
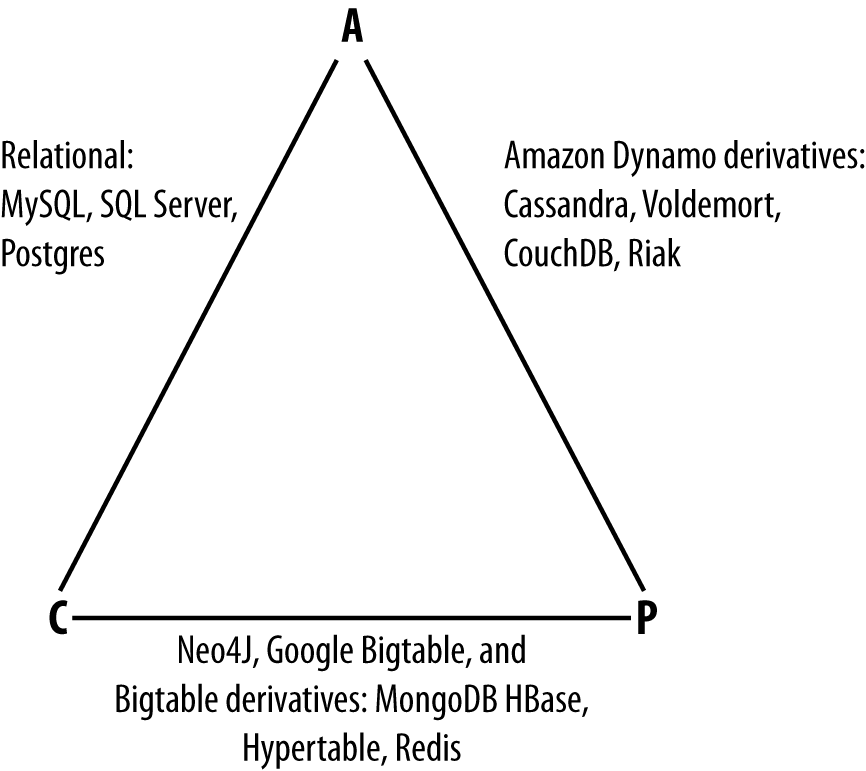
Ultimate question
We should not ask “What’s wrong with relational databases?”, but “What kinds of things would I do with data if it wasn’t a problem?”
So, think different and looking into the future when facing a problem which is different from past ones
Intro to Cassandra
Fifty words to describe Cassandra:
Apache Cassandra is an open source, distributed, decentralized, elastically scalable, highly available, fault-tolerant, tuneably consistent, row-oriented database that bases its distribution design on Amazon’s Dynamo and its data model on Google’s Bigtable. Created at Facebook, it is now used at some of the most popular sites on the Web.
Named after
In Greek mythology, Cassandra was the daughter of King Priam and Queen Hecuba of Troy. Many Cassandra related tools are also named from that mythology.
Some key points of Cassandra
-
Decentralization, therefore, has two key advantages: it’s simpler to use than master/slave, and it helps you avoid outages.
-
Vertical scaling—simply adding more hardware capacity and memory to your existing machine—is the easiest way to achieve this. Horizontal scaling means adding more machines that have all or some of the data on them so that no one machine has to bear the entire burden of serving requests.
-
Elastic scalability: cluster can seamlessly scale up and scale back down.
-
Cassandra is more accurately termed “tuneably consistent,” which means it allows you to easily decide the level of consistency you require, in balance with the level of availability.
The replication factor lets you decide how much you want to pay in performance to gain more consistency. You set the replication factor to the number of nodes in the cluster you want the updates to propagate to (remember that an update means any add, update, or delete operation).
The consistency level is a setting that clients must specify on every operation and that allows you to decide how many replicas in the cluster must acknowledge a write operation or respond to a read operation in order to be considered successful.
-
Dynamo and Cassandra choose to be always writable, opting to defer the complexity of reconciliation to read operations, and realize tremendous performance gains.
Moreover, Cassandra is optimized for excellent throughput on writes.
-
Cassandra’s data model can be described as a partitioned row store, in which data is stored in sparse multidimensional hashtables.
-
Cassandra has out-of-the-box support for geographical distribution of data.
Difference between RDBMS and Cassandra
- No joins
- No referential integrity (no cascading deletes)
- Denormalization fits read-heavy scenarios better than write-heavy.
- Model the queries and let the data be organized around them
- Keep related columns defined together in the same table, a query that searches a single partition will typically yield the best performance
- The sort order available on queries is fixed, and is determined entirely by the selection of clustering columns you supply in the CREATE TABLE command